
Bestands- und Bedarfserhebung im
Forschungsdatenmanagement
Ergebnisse des Projektes FDM-TUDO
Zusammenfassung
Forschungsdatenmanagement (FDM) ist ein dynamischer Prozess, in dem wenige Standardlösungen möglich und etabliert sind. Im Projekt FDM-TUDO wurden von Januar bis Dezember 2018 Anforderungen und Bedarfe von Forschenden im Umgang mit Forschungsdaten mit dem Ziel erhoben, ein bedarfsdeckendes Unterstützungsangebot für die Technische Universität Dortmund (TU Dortmund) zu entwickeln. Leitfadengestützte Interviews mit 62 Professor*innen der TU Dortmund zeigen den Bedarf nach infrastruktureller sowie individueller Unterstützung zur Dokumentation, Speicherung und beim Teilen von Forschungsdaten. Die Forschenden wünschen sich vor allem individuelle Beratung, Workshops, sowie Handreichungen. Im Nachgang des Projektes wurde auf Basis der Ergebnisse ein FDM-Serviceangebot an der TU Dortmund etabliert, um die Anforderungen und Bedarfe der Forschenden zu decken und niedrigschwellige Angebote zu entwickeln. So soll das Potenzial der generierten Daten möglichst umfassend ausgeschöpft werden.
Summary
Research data management (RDM) is a dynamic process in which few standard solutions are possible and established. In the FDM-TUDO project, the requirements and needs of researchers in dealing with research data were surveyed from January to December 2028 with the aim of developing demand-covering support for TU Dortmund University. guideline-based interviews with 62 professors at TU Dortmund University revealed the need for infrastructural and individual support for documenting, storing, and sharing research data. Above all, the researchers would like individual advice, workshops and handouts. As a follow-up to the project, an RDM service was established at TU Dortmund University based on the results in order to meet the requirements and needs of the researchers and to develop low-threshold opportunities to utilise the potential of the generated data as comprehensively as possible.
1. Das Projekt FDM-TUDO
Die Infrastruktur- und Servicelandschaft im Bereich des Forschungsdatenmanagements (FDM) befindet sich in einem stetigen Wandel. Nationale, länderspezifische, sowie institutionelle Bestrebungen erweitern die FDM-Landschaft stetig mit neuen Ansätzen und Lösungen. Beispiele hierfür sind die Nationale Forschungsdateninfrastruktur (NFDI),1 die in verschiedenen Konsortien fachspezifische und fachübergreifende FDM-Lösungen entwickelt, sowie die FDM-Landesinitiativen, unter anderem z.B. fdm.nrw,2 welche die Vernetzung und Weiterbildung von FDM-Personal in Nordrhein-Westfalen vorantreibt. Bevor es diese Initiativen gab, waren Forschende bei der konkreten Ausgestaltung und der Qualitätssicherung ihres Forschungsdatenmanagements häufig auf sich allein gestellt. Im Rahmen
der BMBF-Förderbekanntmachung „Erforschung des Managements von Forschungsdaten in ihrem Lebenszyklus an Hochschulen und außeruniversitären Forschungseinrichtungen“3 wurden die Anforderungen und Bedarfe der Forschenden im Umgang mit Forschungsdaten an mehreren Universitäten erhoben. Das in dieser Förderlinie angesiedelte Projekt FDM-TUDO hatte zum Ziel, den aktuellen Stand des Forschungsdatenmanagements an der Technischen Universität Dortmund (TU Dortmund) zu erheben und darauf aufbauend ein bedarfsgerechtes Unterstützungsangebot auf institutioneller Ebene zu entwickeln.
1.1 Fragestellung der Bedarfserhebung
Im Projekt FDM-TUDO sollte die Ausgestaltung der FDM-Beratungsstelle an der TU Dortmund vorbereitet werden. Hierzu fand eine Befragung der Professor*innen der TU Dortmund mithilfe eines leitfadengestützten Interviews statt. Dabei wurden drei Ziele verfolgt: Erstens sollte die bestehende Forschungspraxis an der TU Dortmund inklusive typischer Prozesse und Anwendungsszenarien als Bestandserhebung erfasst werden. Zweitens sollten in Form einer Bedarfserhebung konkrete Anregungen für ein zu entwickelndes FDM-Angebot seitens der Universität gesammelt werden. Drittens sollte das Interview schließlich als Vermittlungsinstrument Informationen über das FDM bereitstellen. Hierbei stellte die Befragung den ersten Kontakt der Mitarbeitenden des Projektes FDM-TUDO als FDM-Personal der TU Dortmund mit den Forschenden dar und erhöhte so die Awareness für das FDM.
2. Methode
2.1 Studiendesign und Stichprobe
Für die dieser Arbeit zugrundeliegende Befragung wurde ein standardisiertes Interview entwickelt und im Zeitraum von Januar bis Dezember 2018 mit 62 der 80 angefragten von etwa 300 Professor*innen der TU Dortmund durchgeführt.4 Als Zielgruppe der Befragung wurden Professor*innen ausgewählt, um einen breiten Überblick über die verschiedenen Datentypen und -strategien zu bekommen und die Anzahl der Interviews handhabbar zu halten. Darüber hinaus hatte die Befragung auch zum Ziel, die Awareness für FDM zu erhöhen und die Professor*innen als Multiplikatoren für das Thema FDM zu gewinnen. Größtenteils wurden qualitative Daten erhoben; darüber hinaus boten einige Fragen die Möglichkeit quantitativer Angaben.
2.2 Interviewleitfaden
Um eine möglichst hohe Vergleichbarkeit und Nachvollziehbarkeit der Interviews zu erreichen und die Nachnutzbarkeit des Vorgehens zu gewährleisten, wurde ein standardisiertes Interview als Erhebungsinstrument eingesetzt. Auf Basis vorangegangener Befragungen5 wurden Fragen und Antwortoptionen erstellt und iterativ erweitert. Dafür wurden 5 Pilotinterviews mit experimentell, simulativ und theoretisch arbeitenden Professor*innen durchgeführt. Den Abschluss dieser Pilotphase machte eine qualitativ forschende Wissenschaftlerin, die dezidierte Rückmeldung zu allen Aspekten des Interviews geben konnte. Anhand dieser initialen Rückmeldungen wurden die einleitenden Texte, die Dauer und die Antwortoptionen überarbeitet. Weitere Rückmeldungen der Forschenden aus den einzelnen Fachdisziplinen wurden vom FDM-Personal dynamisch eingearbeitet, bis eine diesbezügliche Sättigung erreicht war. Es wurde darauf geachtet, dass jede Fachdisziplin und jede Fakultät zu gleichen Teilen (15–25 % der Professuren pro Fakultät) berücksichtigt und befragt wurde. Dabei wurde eine breite methodische Abdeckung pro Fakultät angestrebt. Der Interviewleitfaden lag nach der initialen Pilotphase bezüglich der Interviewfragen und der Gesprächsführung in seiner finalen Form vor; lediglich Antwortoptionen wurden iterativ ergänzt. Somit stellt er das Ergebnis eines konstruktiven kommunikativ-validierenden Aushandlungsprozesses dar. Der Leitfaden ist in Übereinstimmung mit gängigen Empfehlungen zur Leitfadenkonstruktion in mehrere Phasen aufgeteilt.6 Diese umfassen eine Kennenlern- und Instruktionsphase, eine Warm-up-Phase, eine Hauptphase mit unterschiedlichen inhaltlichen Schwerpunkten sowie eine Ausklang- und Abschlussphase. Der Interviewleitfaden wurde zur Nachnutzung auf Zenodo veröffentlicht.7
2.3 Durchführung
Die Interviews wurden von zwei Personen geführt, wobei die Gesprächsführung variiert wurde, um das Gespräch aufzulockern, während die jeweils andere Person parallel protokollierte. Sämtliche Interviews wurden über Audio aufgezeichnet. Antworten über die vorgegebenen Optionen hinaus wurden als Feldnotizen dokumentiert. Um den Forschenden eine vertraute und angenehme Gesprächsatmosphäre zu ermöglichen, wurden die Interviews vorzugsweise in den Räumlichkeiten der Befragten durchgeführt. Zu Beginn des Interviews wurde in das Thema eingeführt und die jeweilige Frage vorgelesen. Die Erfahrungen und Bedarfe der Interviewten sollten möglichst in einem offenen Format erfasst werden, daher wurden die Antwortoptionen nicht vorgelesen, sondern durch die protokollierende Person auf Basis der Antwort angekreuzt. Die Forschenden sollten ihre Forschungspraxis möglichst ohne Moderation und Einschränkungen schildern können. Wenn Antwortoptionen nicht verfügbar waren, wurden diese unter dem Punkt „Sonstiges“ ergänzt. Wurde diese Antwortoption wiederholt angebracht, wurde dieser Punkt in einer neuen Leitfadenversion ergänzt. Fehlinterpretationen der Antworten durch die Interviewenden wurden durch Nachbesprechung und Abgleich der von den Interviewten parallel gekreuzten Fragebögen vermieden. Bei Unstimmigkeiten zwischen den beiden Interviewenden wurden die Audiomitschnitte konsultiert. Zwischendurch wurden, je nach Kenntnisstand, Informationsblöcke zu verschiedenen FDM-Themen vorgestellt. Ein Interview dauerte ungefähr zwei Stunden.
3. Ergebnisdarstellung und Diskussion
Ausgewählte empirische Forschungserkenntnisse werden hier einerseits aufgrund der großen Stichprobe für eine Interviewstudie (N = 62) mittels quantitativ-deskriptiver Analysen, basierend auf den angekreuzten Antwortoptionen, aufbereitet. Andererseits werden diese Ergebnisse erweitert durch die Hinzunahme der Interviewprotokolle und Audiomitschnitte, sodass auch eine qualitativ-interpretative Auswertung die Interpretation der vorliegenden Daten vervollständigt. Die so dargelegten Befunde werden in den aktuellen wissenschaftlichen Diskurs um das FDM eingeordnet und in Bezug zu neueren empirischen Forschungsergebnissen gesetzt.
3.1 Von der Datenerzeugung bis zur Datenspeicherung –
Prozesse im FDM
Die befragten Professor*innen arbeiten aufgrund der jeweiligen fachlichen Verortung mit sehr unterschiedlichen Forschungsdaten, wobei die Mehrheit diese als empirisch-erzeugte Daten mit oder ohne Personenbezug klassifiziert (48 %). Empirische Daten mit Personenbezug werden laut Aussage der Befragten am häufigsten durch Interview- und Fragebogenstudien generiert. Interessant ist, dass 19 % der Befragten Forschungsdaten nachnutzen und daher bereits Erfahrungen mit nachgenutzten Datensätzen (Sekundärdatensätze) haben (siehe Abbildung 1).8 In den Interviews zeigten sich dabei zwei unterschiedliche Formen der Nachnutzung. Erstens erfolgt eine Nachnutzung häufig intern innerhalb eines Lehrstuhls, indem Datensätze beispielsweise von Doktorand*innen mit Blick auf neue Fragestellungen erneut ausgewertet werden. Zweitens nehmen einige Forschende die Möglichkeit wahr, statistische Daten wie Bevölkerungs- und Sozialdaten von offiziellen Landes- und Bundesbehörden nach zu nutzen.
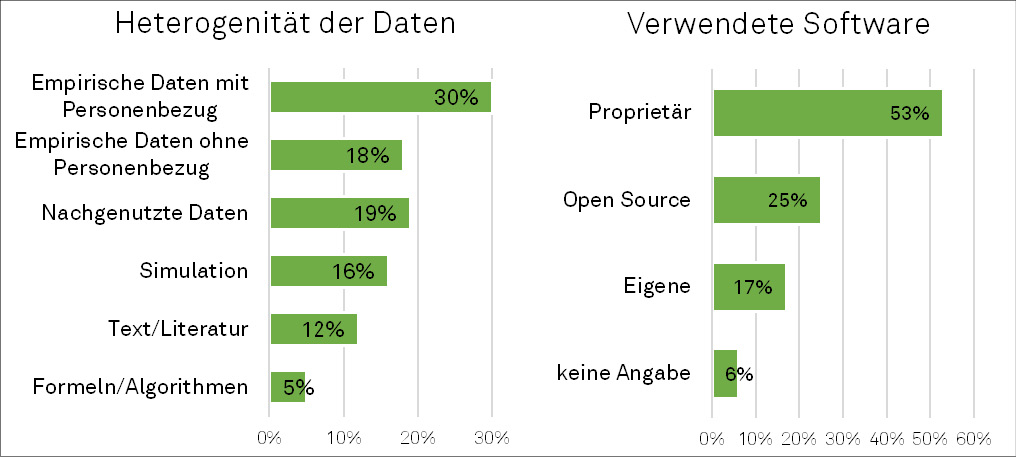
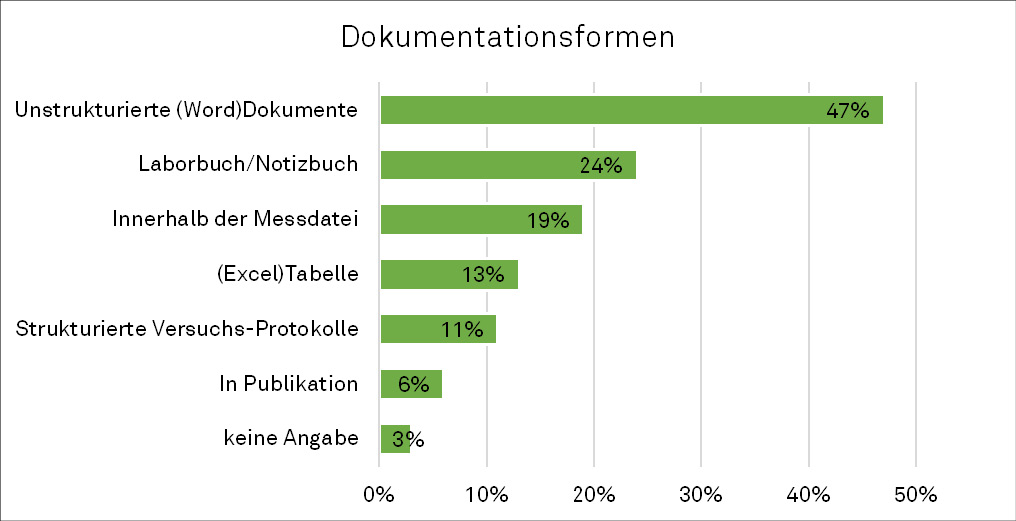
Der typische FDM-Prozess der Interviewten beginnt mit der Erzeugung eigener Daten. Im Anschluss daran erfolgt die zugehörige Datenanalyse. Dies geschieht laut Selbstauskunft am häufigsten in digitaler Form, dabei kommt entsprechende Forschungssoftware zum Einsatz: Die Professor*innen greifen primär auf verfügbare proprietäre Software zurück (siehe Abbildung 1). Hier kommt je nach Forschungsbereich unterschiedliche Software zum Einsatz, wobei die breiteste Verwendung über Fächergrenzen hinaus SPSS, R, Matlab und MAXQDA aufweisen. Die Datendokumentation erfolgt im nächsten Schritt entweder in digitaler, analoger oder in kombinierter Form. Die verwendeten Dokumentationsformen unterscheiden sich dabei je nach Fachgebiet. Primär in der Chemie, Physik und in verwandten Forschungsfeldern sowie in der Psychologie werden bereits standardisierte (elektronische) Laborbücher und strukturierte Versuchsprotokolle verwendet. Ansonsten legt fast die Hälfte der Forschenden die Dokumentation in unstrukturierten (Word-)Dokumenten ab (siehe Abbildung 2). Nur ein Bruchteil der Befragten verwendet dabei fachspezifische Metadatenstandards (3 %). In den qualitativen Antworten kam es jedoch vereinzelt vor, dass die Forschenden von eigenen Schemata sowie projekt- und lehrstuhlinternen Metadaten berichteten. Gleichermaßen wies die Befragung im Rahmen eines parallelen Projekts aus demselben BMBF-Förderprogramm, das Projekt UNEKE, nach, dass über 40 % der Befragten kein vorgegebenes Standardschema nutzen und stattdessen über 40 % auf selbst entwickelte Schemata zurückgreifen.9
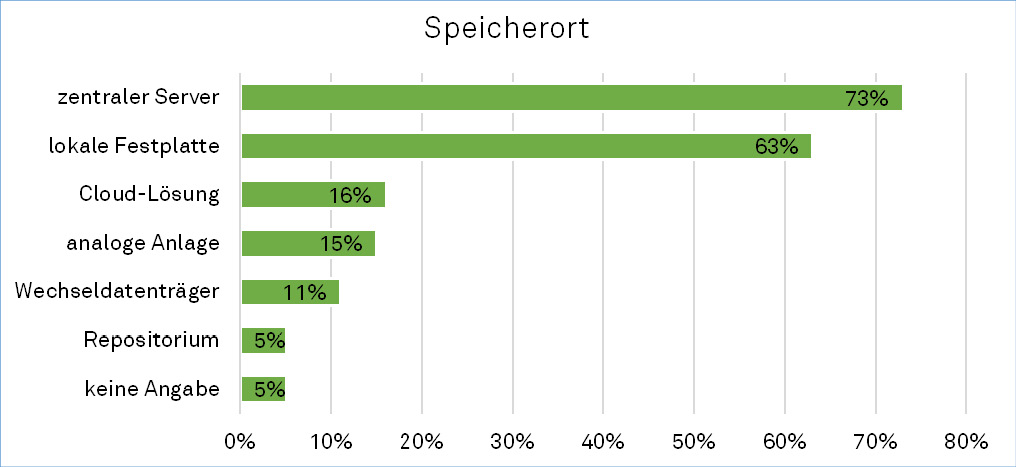
Beim Themenblock der abschließenden Datenspeicherung zeigt sich, dass ein Großteil der Befragten auf die zentralen Server der Universität zurückgreift und diese Form der Speicherung eine breite Nutzer*innenbasis an der TU Dortmund hat (siehe Abbildung 3). In den Interviews wurde dabei deutlich, dass diese Speicheroption aufgrund der integrierten gesicherten Back-up-Strategie und Datensicherheit eine hohe Akzeptanz aufweist. Dieses Angebot ist für die Angehörigen der TU Dortmund aufgrund der festen Zusammenarbeit mit dem IT und Medien Centrum (ITMC) darüber hinaus sehr niedrigschwellig zugänglich. Zudem sind lokale Festplatten ein bevorzugtes Mittel der Speicherung.
Ebenso konnte in einer Befragung an der Christian-Albrechts-Universität zu Kiel 10 belegt werden, dass die lokale Speicherung auf dem dienstlichen Rechner das erste Mittel der Wahl der Befragten ist (67 %).
Am zweithäufigsten wird die Speicherung auf dem Server der Fakultät/ Einrichtung genannt (33 %). Auch an der TU Dortmund werden diese beiden Möglichkeiten am meisten in Anspruch genommen, wobei der zentrale Server (73 %) noch häufiger als die lokale Festplatte (63 %) zum Einsatz kommt. Hier wird deutlich, dass diese beiden Möglichkeiten scheinbar auch parallel genutzt werden. In einer quantitativ ausgerichteten Online-Studie an der TU Berlin11 bestätigt sich eine ähnliche Entwicklung. Auch dort gibt die Mehrheit der Forschenden an, dass der dienstliche Rechner als primäre Speicherquelle dient (86 %) und ebenso die Server des eigenen Instituts (60 %) für diesen Zweck genutzt werden.12 Es wird daher übergreifend deutlich, dass die Forschenden instituts- und universitätsnahe Speichermöglichkeiten sehr häufig nutzen und bevorzugen. Externe Cloud-Lösungen (16 %)
und Repositorien (5 %) sind für die Datenspeicherung noch deutlich weniger im Gebrauch; in den Interviews wurde allerdings nicht erfasst, wie bekannt diese Möglichkeiten sind. Auch in der Studie der Universität Kiel13 nutzen nur wenige Befragte eine externe Cloud-Lösung (10 %) bzw. externe und kommerzielle Datenzentren zur Speicherung (3 %). Allerdings sticht hier die Studie an der TU Berlin14 mit einem anderen Ergebnis hervor, denn dort nutzen vergleichsweise viele Forschende den internen Cloudspeicher der Universität (47 %). Vermuten lässt sich hier, dass interne universitätsweite Cloudlösungen eine höhere Akzeptanz aufweisen als externe Clouddienste, weil sie eine ähnliche Datensicherheit wie die institutionelle Serverspeicherung versprechen, solange eine Universität diese Cloudlösung betreibt und damit institutionelle Data Governance sichert. Daraus lässt sich schließen, dass die Universitäten zukünftig noch stärker in ein solches infrastrukturelles Angebot investieren könnten, um ihren Forschenden institutionelle, sichere Cloud-Lösungen für kollaboratives Arbeiten zur Verfügung zu stellen. Allerdings wünschen sich die Teilnehmenden dieser Interviewstudie aufgrund regelmäßiger nationaler und internationaler Forschungskollaboration ein Infrastrukturangebot, bei dem die Daten nicht nur gespeichert, sondern auch mit externen Projektpartnern ausgetauscht werden können. Der externe Zugriff auf den universitären Dienst müsste daher bei einem Angebot eines institutionellen Cloudservers ebenfalls berücksichtigt werden, damit sich der Clouddienst von einer reinen Speicherlösung abhebt. Dies könnte beispielsweise durch eine Erleichterung des kollaborativen Arbeitens mit Rechte- und Rollenmanagement erfolgen.
3.2 Daten teilen und publizieren – Open Data als notwendiger Entwicklungsschritt
In alltäglichen Arbeitskontexten werden die erzeugten Daten vor allem für die kollegiale Zusammenarbeit bereitgestellt. Der kollaborative Datenaustausch findet auf unterschiedlichen Wegen statt (siehe Abbildung 4).
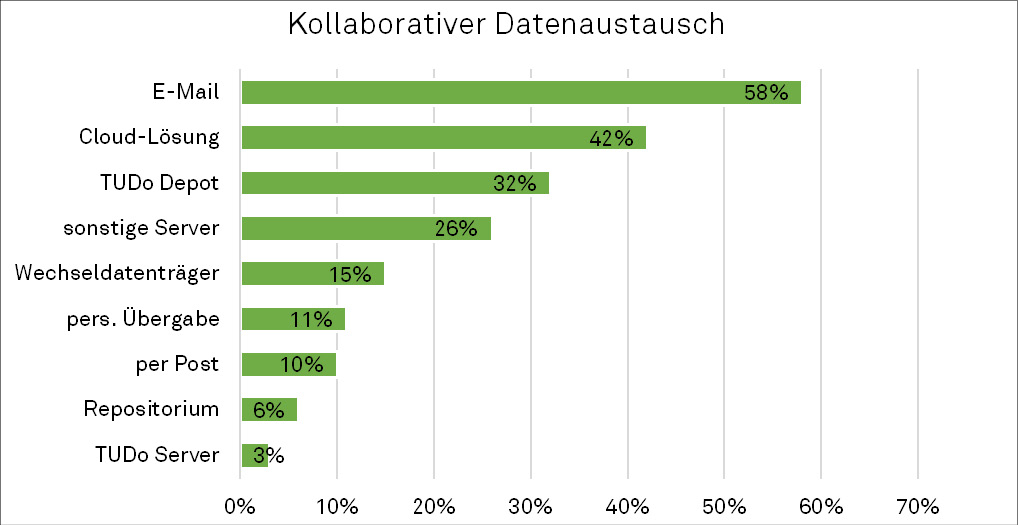
Die Austauschwege reichen von klassischen Formen wie der Post oder der persönlichen Übergabe über die, in der digitalisierten Datenwelt häufig genutzte, Cloudlösung, bis hin zur universitätseigenen Datentransferlösung TUDo Depot. Diese ist jedoch mittlerweile durch die breite Verfügbarkeit von Cloudlösungen wie der NRW-Hochschulcloud Sciebo obsolet geworden.15 Auffällig ist, dass die Mehrheit (58 %) der Interviewten ihre Datensätze via E-Mail austauscht und damit Einschränkungen beim Datenaustausch in Bezug auf Datensicherheit und verfügbares Datenvolumen in Kauf nimmt. Fast die Hälfte der Befragten (40 %) gab zusätzlich an, dass sie Verbesserungsbedarf beim Datenaustausch sehen.
Die erzeugten Daten werden aus verschiedenen Anlässen heraus geteilt. Für die interviewten
Professor*innen ist das Teilen von Forschungsdaten dabei verstärkt durch interne und koopera-
tionsbezogene Tätigkeiten geprägt. Meist werden die Forschungsdaten mit Kolleg*innen desselben Lehrstuhls, bei gemeinsamen Projekten mit Forschungs-/ Industriepartnern oder weiteren Externen geteilt. Im Verhältnis wesentlich seltener werden die Forschungsdaten über Repositorien, Websites oder auf gezielte Anfrage hin mit Externen geteilt (siehe Abbildung 5). Die Weitergabe und Bereitstellung für Externe sowie für die Allgemeinheit nimmt daher zum Erhebungszeitpunkt noch einen vergleichsweise geringen Stellenwert in der Forschungspraxis der Befragten ein.
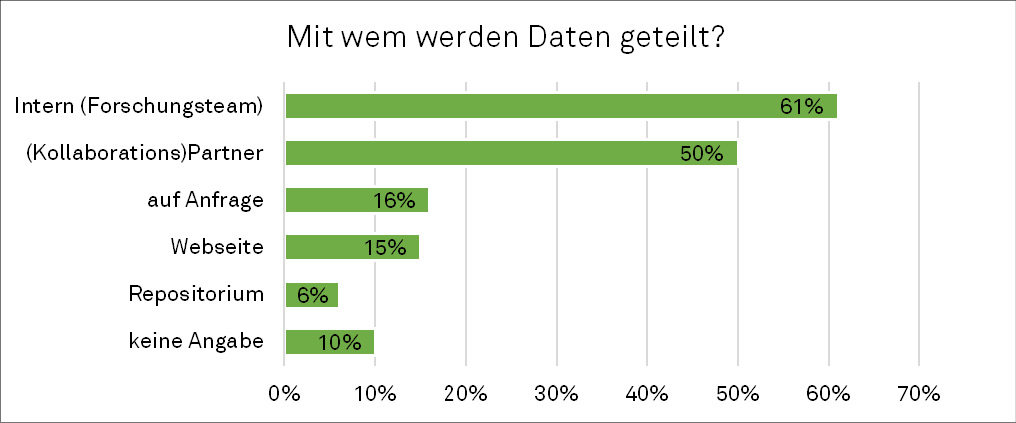
In der Studie von Fecher und Kollegen von 2015 wurde ebenfalls belegt, dass nur 13 % der Befragten ihre Daten öffentlich zugänglich machen.16 Ebenso weist die neuere Studie der Universität Wien nach,17 dass nur 11 % der befragten Forschenden der Universität Wien ihre Daten einer breiten Öffentlichkeit zugänglich macht. Die Professor*innen der hier dargelegten Interviewstudie teilten Daten am häufigsten mit Personen, die gleichzeitig durch interdependente Arbeitsbeziehungen – (Kollaborations-)Partner*innen sowie Kolleg*innen im Forschungsteam – einer gewissen kollegialen Kontrolle unterliegen. Das Teilen von Forschungsdaten ist somit primär durch persönliche Kontakte sowie etablierte vertrauenswürdige Kooperationspraktiken geprägt. So gibt ein Professor beispielsweise direkt an, dass er die Daten „lieber befreundeten Wissenschaftlern zur Verfügung stellt“. Hier wird anhand der begleitenden argumentativen Erzählung der Interviewten deutlich, dass sich die Bereitschaft, Daten zu teilen, erhöht, wenn bereits vertrauensvolle Kontakte hergestellt worden sind. Ebenso zeigt sich bei den früheren, oben genannten Studien, dass rund die Hälfte (46 %) der Befragten es bevorzugen, Daten mit ausgewählten Kolleg*innen derselben Institution zu teilen18 bzw. mit Personen, die sie persönlich kennen (58%).19 In einer Studie an der TU Berlin wurde ebenfalls festgestellt, dass der persönliche Kontakt eine sehr wichtige Rolle für den Austausch von Forschungsdaten spielt.20 So kann resümiert werden, dass Forschende dazu tendieren, Daten mit ihnen bekannten und zugleich als vertrauenswürdig eingeschätzten Personen zu teilen. Einige Repositorien versuchen Vertrauenswürdigkeit durch andere Maßnahmen herzustellen, beispielsweise mittels einer Selbst- und Fremdevaluierung über das CoreTrustSeal.21 Dieses soll allerdings vornehmlich die Qualität, sowie die dauerhafte Auffindbarkeit und Zugänglichkeit der Forschungsdaten sicherstellen. Eine Kontrolle, was mit den Daten nach der Veröffentlichung geschieht, ist, auch im Sinne einer offenen Wissenschaft, nicht vorgesehen. Mögliche Begründungen für ein durch persönliche Kontakte motiviertes Teilen von Daten liefert Michaela Pook-Kolb.22 Sie stellt heraus, dass Wissenschaftler*innen in diesen Fällen eher erwarten können, dass mit ihren Daten gut umgegangen wird und sich eine sekundäre Verwertung nicht nachteilig für sie auswirkt. Zudem werden durch den persönlichen Kontakt aus Sicht der Primärforschenden Fehlinterpretationen von Daten unwahrscheinlicher, da direkte Rücksprachen möglich sind. Hier wird deutlich, dass eine gründliche Dokumentation des Forschungsprozesses in Form von Metadaten, Kontextinformationen sowie beispielsweise, je nach Fachgebiet, Codebüchern und Analysecodes von entscheidender Bedeutung ist, damit die Nachnutzbarkeit von Forschungsdaten gewährleistet ist und nicht von einzelnen Personen abhängt.
Die Veröffentlichung von Forschungsdaten geschieht bei den Befragten dieser Studie im Regelfall im Zusammenhang mit Textpublikationen in Fachjournalen sowie Büchern oder aber auf „Preprint-Servern und in Konferenz-Artikeln“. Noch eher selten kommt die Veröffentlichung separater Datensets durch die interviewten Professor*innen vor. In Projekten, die von der Europäischen Union gefördert wurden, wie z.B. Horizon 2020, wurden aufgrund von Förderverpflichtungen bereits eine Vielzahl der erzeugten Forschungsdaten publiziert. Insgesamt wird je nach Fachbereich sehr unterschiedlich eingeschätzt, wie viel Prozent der erzeugten Daten tatsächlich veröffentlicht werden. Dabei fällt besonders auf, dass vor allem die Forschenden, die aus dem natur- und ingenieurwissenschaftlichen Bereich stammen, in welchem häufig große Datenmengen erzeugt werden, schätzten, dass weniger als 1 % bis 5 % der erhobenen Daten überhaupt veröffentlicht werden. In diesen Fachbereichen gibt es daher ein sehr großes Potenzial für eine Steigerung der Datenpublikationen.
Insgesamt nannten die Interviewten über die Fächergrenzen hinweg unterschiedliche Gründe, die sie von einer Publikation der Forschungsdaten abhalten. Dabei verhindern einerseits ressourcen-bezogene Gründe eine Veröffentlichung, wie fehlendes Personal und begrenzte zeitliche Kapazitäten (siehe Abbildung 6). In den Interviews wurde dabei wiederholt ausgeführt, dass eine aufwändige Datendokumentation und -kuration im Forschungsalltag häufig nicht zu leisten ist. Hier scheint es an Anreizen zu fehlen, Zeit und Ressourcen für die Publikation von Forschungsdaten zu investieren.
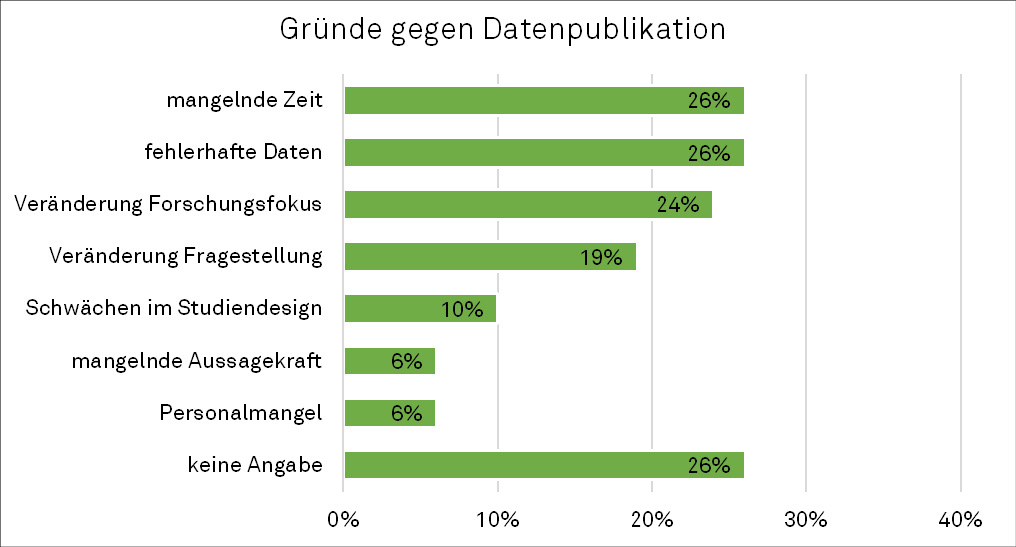
Die Studie der Universität Wien belegt diese Begründung in ähnlicher Weise, da 38 % der dortigen Befragten der erhöhte Aufwand vom Teilen der Daten abhält.23 In der hier dargelegten Interviewstudie wird dies von den Befragten noch weiter spezifiziert, denn neben einem grundsätzlichen Zeitmangel wurde ebenso auf die personelle Fluktuation als weiterer Hinderungsgrund hingewiesen. Ein Professor präzisierte dies und gab an, dass die Datenpublikation „[…] vor allem aufgrund von Zeitdruck und befristeten Verträgen der Wissenschaftler scheitert“. Zudem dominieren andererseits Gründe, die eine Modifizierung des Studiendesigns betreffen wie eine Veränderung des Forschungsfokus oder eine Veränderung der Fragestellung, weshalb einige Forschungsdaten aus Sicht der Forschenden unbrauchbar oder im Prozess verworfen werden. Dazu wurde auch eine mangelnde Aussagekraft der Forschungsdaten als Hinderungsgrund genannt.
In Bezug auf das Teilen von Forschungsdaten deutet sich der Wunsch nach einem Umdenken in der Wissenschaftscommunity an, bei dem auch der Forschungsprozess als Erkenntnisweg honoriert werden soll. An dem folgenden Zitat wird dies deutlich, denn ein Professor hat Vorbehalte, nicht-signifikante Ergebnisse zu veröffentlichen: „Studien, die am Ende nicht das gewünschte Ergebnis bringen, sind schwierig zu veröffentlichen. Ich würde mir zukünftig mehr Anerkennung dafür wünschen, wenn Hypothesen nicht bestätigt werden konnten“. Besonders interessant ist, dass auch Vorbehalte gegenüber der eigenen Daten- und Forschungsqualität eine Publikation verhindern, wie sich bei den Antwortoptionen „Fehlerhafte Daten“ und „Schwächen im Studiendesign“ zeigt. Die Sektion Training & Education der NFDI weist in ihrem Sektionskonzept explizit darauf hin, dass die „Etablierung einer Fehlerkultur in allen Wissenschaftszweigen“ 24 eine wesentliche Voraussetzung dafür ist, damit die Datenpublikation sich in der Breite durchsetzen kann. Die hier präsentierten Ergebnisse untermauern die Relevanz dieser Zielsetzung, da die Forschenden in den Interviews zusätzlich mündlich erläutern, bei der Publikation mängelbehafteter Datensätze um ihre Reputation zu fürchten. Der gesicherte Rückhalt eines akzeptierenden Umgangs mit Fehlern in der Wissenschaft könnte daher die Chance bieten, dass mehr Forschende eine Datenpublikation in Erwägung ziehen und stellt ein wesentliches Entwicklungsziel mit Blick auf offene Datenpublikationen als wichtige Säule der Open Science-Bewegung dar.
Ein anderer Interviewter gab wiederum an, dass er Sorge habe, dass die Datensätze sich doch zu einem späteren Zeitpunkt für weitere Forschungen eignen und man selbst das Potenzial der Datensätze unterschätzt, welches andere dann bereits ausschöpfen. Diese Sorgen bestätigt auch die Studie der Universität Wien.25 Dort berichten 30 % der Forschenden, ihre Daten aufgrund des vermehrten Konkurrenzdrucks nicht zu teilen. In ihrer Studie kann Michaela Pook-Kolb untermauern, dass in hoch-kompetitiven Forschungsfeldern Daten aus Schutz vor Konkurrenzdruck weniger häufig geteilt werden.26 Allerdings geben 76 % der Interviewten der hier dargestellten Studie an, dass sie sich theoretisch vorstellen könnten, ihre unveröffentlichten Daten nach der Einhaltung einer Embargofrist zu veröffentlichen, während es sich nur 14 % nicht vorstellen konnten (10 % machten keine Angaben hierzu). Eine stärkere Aufklärung zur Möglichkeit der Veröffentlichung in Repositorien mit der Option von Embargofristen, der Einschränkung des Nutzerkreises oder des Einsatzes gezielter Nutzungsvereinbarungen könnten daher diesbezügliche Unsicherheiten weiter verringern. So behalten die Forschenden die Kontrolle über ihre Daten und können die Daten zu einem späteren Zeitpunkt oder nur mit Forschenden, die konkrete Verwertungsabsichten offenlegen, teilen.
Demgegenüber wird offenkundig, dass wiederum der Mehrwert der Nachnutzung von Forschungsdaten durchaus erkannt wird. Der Großteil der Teilnehmenden (65 %) dieser Studie hat den Wunsch geäußert, dass Roh- und Primärdaten von anderen Wissenschaftler*innen zur Verfügung gestellt werden. Die Erhebung der TU Berlin belegt noch expliziter, dass 63 % der Befragten bereits Forschungsdaten anderer Wissenschaftler*innen nutzen.27 Von den Befragten an der TU Berlin gaben allerdings zugleich 44 % an, dass sie ihre eigenen Daten wiederum nicht mit der Fachöffentlichkeit teilen wollen. Dort zeigt sich daher ebenso die Diskrepanz zwischen dem Wunsch des Nachnutzens fremder Datensätze bei gleichzeitiger fehlender eigener Datenpublikationsabsicht. Dies wird in der Literatur als ein soziales Dilemma in der Wissenschaft gesehen.28 Für den Einzelnen möge der Aufwand der Datenpublikation zu groß erscheinen, wenn aber alle so handeln würden, dann gäbe es die Vorteile von Open Science und Open Data nicht, von der jedoch viele maßgeblich profitieren. Daher gilt die Empfehlung, die äußeren Anreize für Datenpublikationen zu erhöhen, beispielsweise durch Preise und finanzielle Unterstützung sowie durch die stärkere Etablierung einer Zitationspraxis von Forschungsdaten.29 Eine umfassende quantitative Studie mit Forschenden von 13 deutschen Universitäten von Stieglitz und Kolleg*innen aus dem Jahr 2020 stellte heraus, dass Forschende eher zum Teilen von Daten bereit sind, wenn die Vorteile des Datenteilens die Nachteile überwiegen.30 Dabei waren die erwarteten Vorteile meist auf einen gewünschten Zuwachs der wissenschaftlichen Reputation sowie die Hoffnung auf kollegiale Vernetzung bezogen. Die Forschenden sind daher vor allem zum Teilen von Daten motiviert, wenn sie berufliche Vorteile erwarten sowie dies als Investition in ihre Wissenschaftskarriere verstehen. Bemerkenswert ist hier außerdem, dass der zentrale erwartete Nachteil ebenfalls die Befürchtung negativer Konsequenzen für die eigene Karriere war. Insgesamt scheint die Aussicht auf das Teilen der eigenen Forschungsdaten Ambivalenz hervorzurufen, die gegebenenfalls durch geeignete Anreize aufgelöst werden könnte.
3.3 Unterstützungsmaßnahmen und universitäre FDM-Angebote – Perspektive der Forschenden
Die Professor*innen wurden weiterhin bezüglich gewünschter Unterstützungsmaßnahmen sowie hilfreicher universitärer Angebote zum FDM befragt. Dabei zeigte sich, dass eine Vielzahl unterschiedlicher Unterstützungsformate gewünscht wird. Die persönliche Beratung steht dabei im Fokus. Dabei differenzieren die Interviewten mündlich, dass sie sich primär Einzelberatung (76 %) sowie Workshops (48 %) zu Themenfeldern des Forschungsdatenmanagements wünschen (siehe Abbildung 7). Viele Professor*innen richteten im Gespräch den Blick zudem auf Doktorand*innen als Hauptadressat*innen für mögliche FDM-Maßnahmen. Sie äußerten stellvertretend für diese Zielgruppe einen hohen Bedarf an Beratung, Schulungen sowie unterstützende Leitfäden. In der Studie der Universität Wien wurde bereits nachgewiesen, dass primär studentische Mitarbeiter*innen sowie Doktorand*innen sich Workshops bzw. Schulungsangebote zum FDM wünschen.31
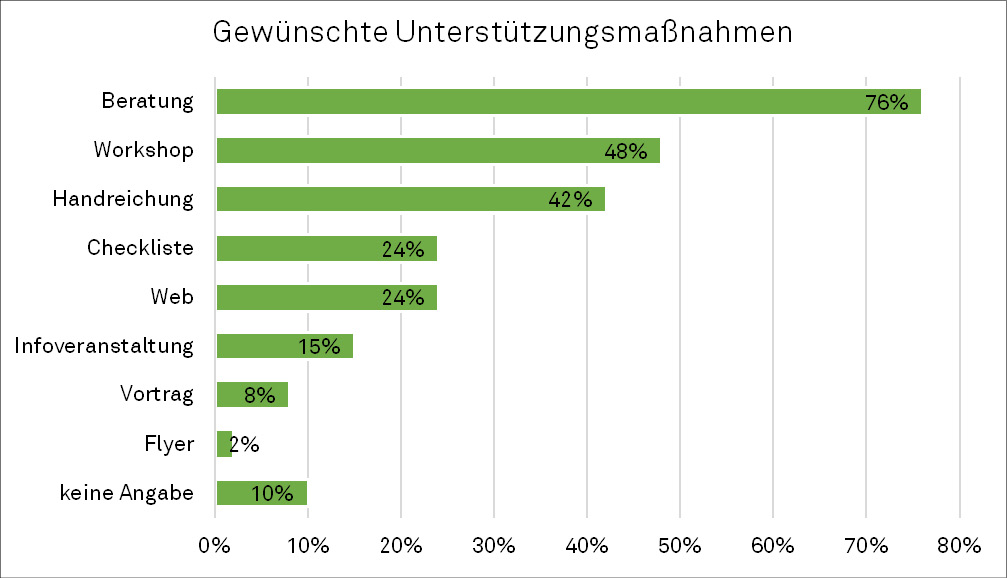
Die Professor*innen selbst äußerten hier vermehrt den Wunsch nach direkter Antragsberatung. Für sie steht die Beratung zu den Vorgaben der Forschungsförderer zum FDM sowie die konkrete Unterstützung zum Datenhandling in Projekten stärker im Fokus als grundlegende Einführungskurse zu diesem Thema. Auch in der Studie der TU Berlin kamen die gleichen Unterstützungsleistungen im FDM bei den Forschenden auf über 70 % positive Gewichtung: Anforderungen der Mittelgeber (73 %) sowie Beratung in der Projektantragsphase (72 %).32
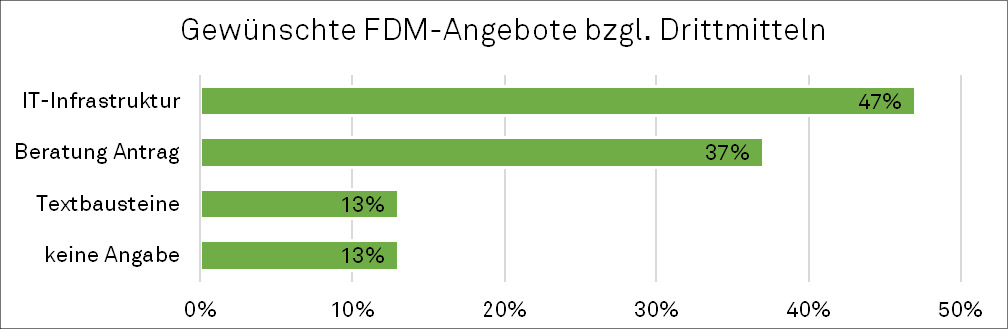
Auf gezielte Nachfrage zur Unterstützung bei Drittmittelprojekten wurde konkretisiert, dass fast die Hälfte der Befragten Unterstützung im IT-Bereich sowie mehr als ein Drittel eine gezielte Antragsberatung wünscht (siehe Abbildung 8). Einige Teilnehmende wünschen sich darüber hinaus die Identifizierung von Best-Practice-Beispielen zur Orientierung und möglichen Nachahmung. Die Befragten äußerten an dieser Stelle wiederholt, von den Erfahrungen anderer lernen zu wollen.
Nahezu alle Interviewten wollen zudem gerne regelmäßig über Neuerungen im FDM an der eigenen Universität informiert werden und am häufigsten wird die Form eines E-Mail-Newsletters bevorzugt. Dieser Newsletter sollte laut Aussage einiger Befragten nicht nur reine Informationen erhalten, sondern auch konkrete Schulungsangebote und Veranstaltungshinweise beinhalten. Dabei gaben die meisten an, dass sie nicht mit Informationen überfrachtet, sondern über essentielle Neuerungen informiert werden wollten.
Insgesamt stellt sich in den Interviews heraus, dass es ein großes Interesse an Unterstützungsmaßnahmen gibt, die dabei laut den Befragten eine zielgruppenspezifische Ausrichtung aufweisen sollten.
4. Entwicklung des FDM an der TU Dortmund
Zum Zeitpunkt der Interviews im Jahre 2018 waren systematisierte Konzepte und zentrale Unterstützungsangebote bezüglich FDM an den deutschen Hochschulen weit weniger etabliert als heute.33 Basierend auf den eigenen Ergebnissen und prototypischen Lösungen im Projekt FDM-TUDO und den Erkenntnissen vorangegangener Studien und der Schwesterprojekte aus der gleichen Förderlinie wurde an der TU Dortmund ein initiales Beratungs- und Unterstützungsangebot aufgebaut, welches im laufenden Betrieb immer weiter ausdifferenziert wurde und als Grundlage für den im Jahr 2020 gegründeten Forschungsdatenservice diente. Dieser startete als zentrale Anlaufstelle zwischen dem Referat Forschungsförderung, dem ITMC und der Universitätsbibliothek und wurde bis zum Jahr 2022 zwischen der neuen Abteilung Forschungsdatenmanagement, dem ITMC und der Universitätsbibliothek umstrukturiert und bedarfsgerecht skaliert. Die Gestaltung einer zentralen Anlaufstelle mit einer gemeinsamen Funktions-Emailadresse entsprang der service-orientierten Einstellung, den Forschenden eine Suche nach der korrekten Ansprechperson zu ersparen und so eine unkomplizierte Kommunikation zu ermöglichen. Im Jahr 2019 veröffentlichte die TU Dortmund eine Policy34 über die Grundsätze des Umgangs mit Forschungsdaten, die auch die FAIR Prinzipen umfasst.35 Die Forschenden sind dazu angehalten, die Daten möglichst auffindbar (findable), zugänglich (accessible), interoperabel (interoperable), und nachnutzbar (reusable) zu gestalten. Obwohl die FAIR Prinzipien zum Zeitpunkt der Interviews noch nicht weit verbreitet waren, waren schon erste Schritte in Richtung FAIRer Daten erfolgt. Es gab bereits eine grundlegende Einsicht und Bereitschaft an der TU Dortmund, die FAIR Prinzipen für Forschungsdaten anzuwenden, allerdings fehlten noch bedarfsgerechte Lösungen, um dies den Forschenden so einfach wie möglich zu machen. Im Anschluss an die vorliegende Bedarfserhebung wurden Lösungen vor Ort entwickelt sowie vorhandene Lösungen implementiert: Um die Auffindbarkeit von Daten zu erhöhen, vermittelt der Forschungsdatenservice der TU Dortmund sowohl in Beratungsgesprächen als auch in Workshops Lösungen und Kompetenzen. Hierbei erwies sich, basierend auf den Erfahrungen durch die Interviews, besonders der persönliche, analoge Kontakt als hilfreich, um ein kooperatives, ertragreiches Gespräch aufzubauen. Die Workshops umfassen Grundlagenworkshops, die den gesamten Forschungsdatenlebenszyklus abdecken, sowie vertiefende Veranstaltungen, die flexibel aktuellen Anforderungen gerecht werden. Das Workshop-Programm ist außerdem Teil des Universitätsallianz Ruhr (UA Ruhr)-übergreifenden Schulungsprogramms „FDM-Curriculum“ ,36 das die Kompetenzen und Bedarfe hochschulübergreifend verbindet. Das universitätseigene Repositorium Eldorado37 bietet über die Vergabe von Digital Object Identifier (DOI) die Möglichkeit, Datensätze persistent auffindbar und zitierbar zu machen. Bezüglich der Zugänglichkeit zeigte sich, dass die Daten häufig nur mit Kolleg*innen oder Kooperationspartner*innen geteilt werden. Im Nachgang der Befragungen wurde an der TU Dortmund die EU-Lösung B2Drop als Clouddienst über die zentrale universitäre Authentifizierung eingeführt, um den Forschenden zeitnah eine sichere Cloud-Lösung für das Teilen von Daten mit Kolleg*innen anzubieten. Um die Zugänglichkeit und Nachnutzbarkeit von Daten auch für externe Forschende zu erhöhen, weist der Forschungsdatenservice vermehrt auf die Vorteile einer Publikation in Repositorien hin und unterstützt bei der Suche nach einem angemessenen Repositorium für die jeweiligen Forschungsdaten, beispielsweise im eigenen Open Access-Repositorium Eldorado, in einem generischen Repositorium wie Zenodo38, oder in einem fachspezifischen Repositorium.39 Auch bezüglich der Interoperabilität wurde Verbesserungspotenzial identifiziert. Häufig werden proprietäre Formate genutzt, die eine Nachnutzung und Analyse oder Aggregation durch Dritte problematisch macht. Auch werden kaum Metadaten verwendet, die das Potenzial haben, den Datensatz besser auffindbar zu machen, sowie die Relevanz eines Datensatzes für Nachnutzende herauszustellen.
In Bezug auf die Awareness für FDM wurden auf Basis der Interviews mehrere Maßnahmen umgesetzt. Da die Interviewten angaben, von den Erfahrungen anderer in Bezug auf das FDM lernen zu wollen, ist an der TU Dortmund die Ernennung von Data Champions umgesetzt worden, um Wissenschaftler*innen mit Erfahrungen im FDM als Vorreiter*innen bekannt zu machen und auf innovative Lösungswege sowie gelungene FDM-Strategien hinzuweisen.40 Weiterhin wurde, basierend auf den Rahmenbedingungen, die in den Interviews ermittelt wurden, im Jahr 2023 eine FDM-Mailingliste an der TU Dortmund ins Leben gerufen, in der mehrmals im Jahr, basierend auf den relevanten Inhalten, interessierte Forschende über die genannten Inhalte informiert werden.
Insgesamt zeigt sich in den Interviews, dass die Forschenden motiviert sind, angemessenes FDM zu betreiben, die Unterstützung sstrukturen jedoch noch nicht breit genug ausgebaut waren – sowohl auf nationaler als auch universitärer Ebene. Aufgrund der Heterogenität der Forschungsdaten und der möglichen Lösungen halten viele Forschende eine individuelle Beratung und unkomplizierten IT-Support für besonders hilfreich. Durch die Knappheit an finanziellen, personellen sowie zeitlichen Ressourcen scheinen häufig einfache Wege gewählt zu werden, auch wenn diese nicht den optimalen Nutzen aus den Daten gewährleisten (z.B. Speicherung auf dem Universitätsserver und Versand per Email statt Aufbereitung der Daten und Verfügbarmachung in der Cloud oder im Repositorium). Um den gesamten Verwaltungsprozess der Forschungsdaten zu erleichtern, wurde im Rahmen des Projektes außerdem der Research Data Management Organizer (RDMO) in Kooperation mit den Universitäten der Universitätsallianz Ruhr (UA Ruhr) eingeführt. RDMO ist ein Werkzeug zur Erstellung von Datenmanagementplänen, das gleichzeitig ein Übersicht über das FDM über die gesamte Projektdauer hinaus ermöglicht und somit eine Kontrolle über den aktuellen Stand des FDM gewährleistet.41 Dieser wird den Interessent*innen außerdem fortlaufend in Workshops und Beratungen nähergebracht. Das auf Basis der Interviews aufgebaute Service- und Beratungsangebot der TU Dortmund unterstützt die Forschenden bedarfsorientiert dabei, ihre Daten FAIRer zu machen – aufgrund der diversen Anforderungen und Standards der Fachdisziplinen ist hierbei eine individuelle Beratung von zentraler Bedeutung.
5. Ausblick und Fazit
Aus der vorliegenden Befragung ergeben sich vielfältige weitere Fragestellung und Forschungspotenziale. Auf Basis der Interviews sowie den Erfahrungen der Mitarbeiter*innen im Projekt wurden beispielsweise prototypische FDM-Workflows konzipiert, die an anderer Stelle veröffentlicht werden. Die Workflows beschreiben den Lebenszyklus von Forschungsdaten je nach Arbeitsweise. Weiterhin könnte eine zukünftige Bestands- und Bedarfserhebung aufzeigen, welche Verbesserungen sich im FDM in der Zwischenzeit ergeben haben und welche aktuellen Bedarfe und Wünsche neu entstanden sind. Zusammenfassend lässt sich festhalten, dass unter den Professor*innen eine grundlegende Bereitschaft vorhanden ist, FAIRe Daten zu gewährleisten. Bei den begrenzten zeitlichen und finanziellen Ressourcen ist es jedoch der Auftrag von Hochschulen und des FDM-Personals, zugängliche und unkomplizierte Lösungen bereitzustellen und den FDM-Prozess zu unterstützen.
Literaturverzeichnis
- Arndt, Witold; Gerlich, Silke Christine; Hofmann, Volker u.a.: A survey on research data management practices among researchers in the Helmholtz Association, Kiel, Germany, 2022 (HMC Report). Online: https://doi.org/10.3289/HMC_publ_05.
- Fecher, Benedikt; Friesike, Sascha; Hebing, Marcel u.a.: A reputation economy. Results from an empirical survey on academic data sharing, DIW Discussion Papers, 1454, 2015. Online: https://www.econstor.eu/handle/10419/107687, Stand: 08.03.2024.
- Herres-Pawlis, Sonja; Pelz, Peter; Kockmann, Norbert u.a.: Sektionskonzept Training & Education zur Einrichtung einer Sektion im Verein Nationale Forschungsdateninfrastruktur (NFDI) e.V., 2022. Online: https://doi.org/10.5281/zenodo.6475541.
- Kalová, Tereza: Forschende und ihre Daten, 2020. Online: https://doi.org/10.25365/phaidra.
236. - Kletke, Olaf; Larres, Inga; Höhner, Kathrin u.a.: Interviewleitfaden zur Bestands- und Bedarfserhebung im Forschungsdatenmanagement (FDM) – Projekt FDM-TUDO, 2022. Online: https://
doi.org/10.5281/zenodo.6961593. - Kuberek, Monika; Otto, Dagmar; Steffen, Ronald: Bedarfserhebung zu Forschungsdaten an der TU Berlin, 2021. Online: https://doi.org/10.14279/depositonce-11307.
- Linek, Stephanie B.; Fecher, Benedikt; Friesike, Sascha u.a.: Data sharing as social dilemma: Influence of the researcher’s personality, in: PLoS ONE 12 (8), 2017, e0183216. Online: https://doi.org/10.1371/journal.pone.0183216.
- Neuroth, Heike; Oevel, Gudrun: Aktuelle Entwicklung und Herausforderungen im Forschungsdatenmanagement in Deutschland, in: Putnings, Markus; Neuroth, Heike; Neumann, Janna (Hg.):
Praxishandbuch Forschungsdatenmanagement, Berlin; Boston 2021, S. 537–556. - Pappenberger, Karlheinz: bwFDM-Communities. Wissenschaftliches Datenmanagement an den
Universitäten Baden-Württembergs, in: Bibliothek Forschung und Praxis 40 (1), 2016, S. 21–25. Online: https://doi.org/10.1515/bfp-2016-0017. - Pook-Kolb, Michaela: Teilen oder nicht teilen. Die Logik des Schützens von Forschungsdaten,
2021. Online: https://link.springer.com/book/10.1007/978-3-658-35300-1, Stand: 08.03.2024. - Renner, Karl-Heinz; Jacob, Nora-Corina: Das Interview. Grundlagen und Anwendung in Psychologie und Sozialwissenschaften, Berlin, Heidelberg (Basiswissen Psychologie). Online: https://link.springer.com/book/10.1007/978-3-662-60441-0, Stand: 08.03.2024.
- Stieglitz, Stefan; Wilms, Konstantin; Mirbabaie, Milad u.a.: When are researchers willing to share their data? Impacts of values and uncertainty on open data in academia, in: PLoS ONE 15 (7), 2020, e0234172. Online: https://doi.org/10.1371/journal.pone.0234172.
- Weng, Franziska; Thoben, Stella; Paul-Stüve, Thilo u.a.: Ergebnisse der Umfrage zum Umgang mit digitalen Forschungsdaten in Schleswig-Holstein, 2018. Online: https://doi.org/10.5281/zenodo.1216810.
- Wilkinson, Mark D.; Dumontier, Michel; Aalbersberg, I. Jsbrand Jan u.a.: The FAIR Guiding Principles for scientific data management and stewardship, in: Scientific Data 3 (1), 2016, S. 160018. Online: https://doi.org/10.1038/sdata.2016.18.
- Wilms, Konstantin; Brenger, Bela; Lopéz, Ania u.a.: UNEKE – Umfrage zur Speicherpraxis und Speicherbedarfen für Forschungsdaten, 2020. Online: https://doi.org/10.4232/1.13327.
1 Nationale Forschungsdateninfrastruktur (NFDI): https://www.nfdi.de/, Stand: 08.03.2024.
2 Landesinitiative Forschungsdatenmanagement fdm.nrw: https://fdm-nrw.coscine.de/, Stand: 08.03.2024.
3 Bekanntmachung des BMBF vom 15.08.2016: https://www.bmbf.de/foerderungen/bekanntmachung-1233.html, Stand: 08.03.2024.
4 Wir wurden mehrfach darum gebeten, unsere spannenden Ergebnisse und den Fragebogen zu veröffentlichen, damit unsere Kenntnisse nachgenutzt werden können. Deshalb haben wir den Fragebogen bereits 2022 über Zenodo veröffentlicht (s. Fußnote 7), für die Veröffentlichung einer Fachpublikation fehlten aber bislang die personellen Ressourcen.
5 Pappenberger, Karlheinz: bwFDM-Communities. Wissenschaftliches Datenmanagement an den Universitäten Baden-Württembergs, in: Bibliothek Forschung und Praxis 40 (1), 2016, S. 21–25. Online: https://doi.org/10.1515/bfp-2016-0017.
6 Renner, Karl-Heinz; Jacob, Nora-Corina: Das Interview. Grundlagen und Anwendung in Psychologie und Sozialwissen-
schaften, Berlin, Heidelberg (Basiswissen Psychologie). Online: https://link.springer.com/book/10.1007/978-3-662-60441-0, Stand: 08.03.2024.
7 Kletke, Olaf; Larres, Inga; Höhner, Kathrin u. a.: Interviewleitfaden zur Bestands- und Bedarfserhebung im Forschungs-
datenmanagement (FDM) – Projekt FDM-TUDO, 2022. Online: https://doi.org/10.5281/zenodo.6961593.
8 Anm.: Die Abbildungen beziehen sich auf die quantitativen Teile der Befragung, während Ergebnisse aus den qualitativen Teilen im Fließtext erläutert werden.
9 Wilms, Konstantin; Brenger, Bela; Lopéz, Ania u.a.: UNEKE – Umfrage zur Speicherpraxis und Speicherbedarfen für Forschungsdaten, 2020. Online: https://doi.org/10.4232/1.13327.
10 Weng, Franziska; Thoben, Stella; Paul-Stüve, Thilo u. a.: Ergebnisse der Umfrage zum Umgang mit digitalen Forschungs-
daten in Schleswig-Holstein , 2018. Online: https://doi.org/10.5281/zenodo.1216810.
11 Kuberek, Monika; Otto, Dagmar; Steffen, Ronald: Bedarfserhebung zu Forschungsdaten an der TU Berlin, 2021. Online: https://doi.org/10.14279/depositonce-11307.
12 Arndt, Witold; Gerlich, Silke Christine; Hofmann, Volker u. a.: A survey on research data management practices
amongresearchers in the Helmholtz Association, Kiel, Germany, 2022 (HMC Report). Online: https://doi.org/
10.3289/HMC_publ_05.
13 Weng, Thoben, Paul-Stüve u. a.: Ergebnisse der Umfrage zum Umgang mit digitalen Forschungsdaten in Schleswig-Holstein, 2018.
14 Kuberek, Otto, Steffen: Bedarfserhebung zu Forschungsdaten an der TU Berlin, 2021.
15 Sciebo, https://hochschulcloud.nrw/, Stand: 08.03.2024.
16 Fecher, Benedikt; Friesike, Sascha; Hebing, Marcel u.a.: A reputation economy. Results from an empirical survey on
academic data sharing, DIW Discussion Papers, 1454, 2015. Online: https://www.econstor.eu/handle/10419/107687.
17 Kalová, Tereza: Forschende und ihre Daten, 2020. Online: https://doi.org/10.25365/phaidra.236.
18 Ebd.
19 Fecher, Friesike, Hebing u.a.: A reputation economy. Results from an empirical survey on academic data sharing, 2015.
20 Kuberek, Otto, Steffen: Bedarfserhebung zu Forschungsdaten an der TU Berlin, 2021.
21 Core Trust Seal, https://www.coretrustseal.org/, Stand: 08.03.2024
22 Pook-Kolb, Michaela: Teilen oder nicht teilen: Die Logik des Schützens von Forschungsdaten, 2021. Online: https://link.springer.com/book/10.1007/978-3-658-35300-1, Stand: 08.03.2024.
23 Kalová: Forschende und ihre Daten, 2020.
24 Herres-Pawlis, Sonja; Pelz, Peter; Kockmann, Norbert u.a.: Sektionskonzept Training & Education zur Einrichtung einer Sektion im Verein Nationale Forschungsdateninfrastruktur (NFDI) e.V., 2022. Online: https://doi.org/10.5281/zenodo.6475541, S. 3.
25 Kalová: Forschende und ihre Daten, 2020.
26 Pook-Kolb: Teilen oder nicht teilen: Die Logik des Schützens von Forschungsdaten, 2021.
27 Kuberek, Otto, Steffen: Bedarfserhebung zu Forschungsdaten an der TU Berlin, 2021.
28 Linek, Stephanie B.; Fecher, Benedikt; Friesike, Sascha u.a.: Data sharing as social dilemma: Influence of the researcher’s personality, in: PLoS ONE 12 (8), 2017, e0183216. Online: https://doi.org/10.1371/journal.pone.0183216.
29 Ebd.
30 Stieglitz, Stefan; Wilms, Konstantin; Mirbabaie, Milad u.a.: When are researchers willing to share their data? Impacts of values and uncertainty on open data in academia, in: PLoS ONE 15 (7), 2020, e0234172. Online: https://doi.org/
10.1371/journal.pone.0234172.
31 Kalová: Forschende und ihre Daten, 2020.
32 Kuberek, Otto, Steffen: Bedarfserhebung zu Forschungsdaten an der TU Berlin, 2021.
33 Neuroth, Heike; Oevel, Gudrun: Aktuelle Entwicklung und Herausforderungen im Forschungsdatenmanagement in Deutschland, in: Putnings, Markus; Neuroth, Heike; Neumann, Janna (Hg.): Praxishandbuch Forschungsdatenmanagement, Berlin; Boston 2021, S. 537–556.
34 Grundsätze des Forschungsdatenmanagement an der TU Dortmund: https://www.tu-dortmund.de/forschung/
forschungsdatenmanagement/grundsaetze-des-forschungsdatenmanagements/, Stand: 08.03.2024.
35 Wilkinson, Mark D.; Dumontier, Michel; Aalbersberg, I. Jsbrand Jan u.a.: The FAIR Guiding Principles for scientific
data management and stewardship, in: Scientific Data 3 (1), 2016, S. 160018. Online: https://doi.org/10.1038/sdata.
2016.18.
36 Forschungsdatenmanagement UA Ruhr, https://dev.uaruhr.de/forschung/Forschungsdatenmanagement.html.de, Stand: 08.03.2024.
37 Eldorado – Repositorium der TU Dortmund: https://eldorado.tu-dortmund.de/, Stand: 08.03.2024.
38 Zenodo, https://zenodo.org/, Stand: 08.03.2024.
39 Hier erfolgt die Recherche beispielsweise über das Repositorienverzeichnis re3data: https://www.re3data.org/, Stand: 08.03.2024.
40 Data Champions an der TU Dortmund, https://fdm.tu-dortmund.de/fdm-an-der-tu-dortmund/data-champions/, Stand: 08.03.2024.
41 RDMO der UA Ruhr, https://rdmo.uaruhr.de/, Stand: 08.03.2024.

