
Digital Scholarship Services
Neue Dienstleistungen von wissenschaftlichen Bibliotheken für
die datenbasierte Forschung
Zusammenfassung
Der Begriff Digital Scholarship beschreibt die umfassende Transformation von Wissenschaftspraxen durch digitale, insbesondere datengetriebene Methoden. Forschende arbeiten mit spezifischen Datenbeständen, nutzen Data-Science-Methoden und Big-Data-Anwendungen. Um diesen Entwicklungen gerecht zu werden, sind wissenschaftliche Bibliotheken aufgerufen, eigene und erworbene Bestände strukturiert als Datenkonvolute aufzubereiten und einfach zu nutzende Zugänge zu diesen zu schaffen, entsprechende Werkzeuge und Infrastrukturen der Data Science vorzuhalten und Forschung, Lehre und Öffentlichkeit bei deren Nutzung beratend und vermittelnd zu unterstützen.
Die Universitätsbibliothek Bern baut im Rahmen der universitären Digitalisierungsstrategie solche Services zur Unterstützung von Digital Scholarship auf. Grundlagen hierfür bilden neuere Konzepte wie Collections as Data und die Vermittlung von Digital Literacy. Der Beitrag erläutert zunächst das Konzept der Digital Scholarship und gibt einen Überblick über deren Voraussetzungen. Zentral werden Herausforderungen und Chancen in wissenschaftlichen Bibliotheken diskutiert, die Services für die datengetriebene Forschung bieten. Schließlich werden der Aufbau der Digital Scholarship Services und das aktuelle Service-Angebot der Universitätsbibliothek Bern vorgestellt und erste Erfahrungen rekapituliert.
Summary
The term Digital Scholarship is used to describe the comprehensive transformation of scholarly practice through digital, particularly data-driven methods. Research requires specific data volumes and uses data science methods and big data applications. In order to do justice to these developments, academic libraries are called upon to rework both their own and acquired collections in a structured way as data packages. They should also create easy-to-use access points to these, provide the necessary tools and infrastructures for data science, and give advice and support to researchers, lecturers and the public who want to use them.
The University Library of Bern is developing such services to support Digital Scholarship as part of the university’s digital transformation strategy. The basis for this are current concepts such as Collections as Data and digital literacy education. The article first explains the concept of Digital Scholarship and gives an overview of its prerequisites. The focus is on the discussion of challenges and opportunities that arise in academic libraries with services for data-driven research. Finally, the development of the Digital Scholarship Services and the current range of services offered by the University Library of Bern are presented and initial experiences are recapped.
1. Digital Scholarship als datengetriebene Wissenschaft
1.1 Das Konzept Digital Scholarship
Datengetriebene Methoden bewirken aktuell eine tiefgreifende Transformation in so gut wie allen Wissenschaftsdisziplinen.1 Im anglo-amerikanischen Raum werden diese Entwicklungsprozesse, die neue Forschungszugänge hervorbringen, neue Rahmenbedingungen erfordern und manche Disziplinen mit ganz neuen Forschungsparadigmen konfrontieren, unter dem Begriff der Digital Scholarship (DS) zusammengefasst. Digital Scholarship als durch die Digitalisierung induzierte Transformation von wissenschaftlichen Praktiken wurde breit thematisiert, gerade auch im Hinblick auf die Arbeit von wissenschaftlichen Bibliotheken.2 Insbesondere wurde das Konzept bereits 2007 von Christine Borgman umfassend analysiert und zurückgeführt auf die transformative Kraft der vernetzten Informationstechnologie, indem sie konstatiert „The internet lies at the core of an advanced scholarly information infrastructure to facilitate distributed, data and information-intensive collaborative research“.3 Laut Borgman wird Scholarship als umfassend verstandenes Funktionssystem der Wissenschaften zukünftig daten- und informationsintensiv, verteilt, interdisziplinär und kollaborativ gestaltet sein. Bemerkenswerterweise thematisiert Borgman hier bereits die zentrale Rolle von Daten als „input and output of scholarship“4 – entgegen der damalig noch klar dokumentenzentrierten wissenschaftlichen Austauschprozesse. Diese Argumentation führt sie 2015 explizit fort und prägt den Begriff Data Scholarship neu.5 Wo Daten zum zentralen Moment der Forschung werden, entstehen neue Fragen zu Eigentum, Kontrolle und Zugang, zu Nachhaltigkeit und Validität in verschiedenen Kontexten wie auch durch technologische und wissenschaftspolitische Verschiebungen.6 Die Verquickung von Daten und Wissenschaft ist unausweichlich und formt sich in volatilen Wissensinfrastrukturen aus, die sich in ständigem Wandel befinden.7
Wie stark traditionelle Forschungssysteme durch die Fokussierung auf Daten überformt werden, lässt sich besonders an den Digital Humanities beobachten, die sich durch die Anwendung von digitalen, datenbasierten Methoden in den Geisteswissenschaften auszeichnen.8 Exemplarisch wird dies im Aufsatz von Romain u.a. (2020)9 zum State-of-the-field der Digital History deutlich. Basis der digital-historischen Forschung sind Daten: Diese müssen oft erst erstellt und in adäquate Strukturen transformiert werden (Datafizierung). Daraufhin können sie z.B. mit Text- und Netzwerkanalyseverfahren untersucht werden. Diese für die Geschichtswissenschaft neuen Methoden haben explizite Auswirkungen auf Wissensinfrastrukturen im Borgmanschen Sinn. Neben einer geschärften digitalen Hermeneutik weisen Romein u.a. (2020) insbesondere auf kollaborative und interdisziplinäre Arbeitsprozesse hin, die sich auch in geänderten Publikationspraxen niederschlagen sowie in der Notwendigkeit zur Weiterqualifizierung von Forschenden und zur Anpassung von Ausbildungsgängen.10
Die Datenzentriertheit der DS manifestiert sich folglich auf zweifache Weise: Zum einen rücken Daten als Untersuchungsgegenstand in den Mittelpunkt der Forschung und gewinnt ihre Herstellung durch Datafizierung zentral an Bedeutung, zum anderen kommen datenbasierte Techniken als Analyse- und Synthesemethoden zum Einsatz. Auf diese beiden Ebenen rekurriert ebenfalls die Digital-Scholarship-Definition von Senseney u.a. (2021) im Glossar des Berichtes Transforming library services for computational research with text data:
A broad term that for purposes of this paper relates to the variety of ways in which “digital evidence” and computational methods are incorporated into academic research. Generally speaking, it is used to evoke scholarly behavior and practice in which digital objects, data, or workflows (i.e., analysis techniques) are a primary component of the research project.11
Pinfield u.a. (2017) denken in ihrem Bericht Mapping the future of academic libraries: a report for SCONUL noch weiter voraus und beschreiben den Nexus “datafied scholarship” als einen zentralen Megatrend für Bibliotheken. In ihrer Charakterisierung tritt neben die beiden genannten Aspekte noch zentral die Ebene der Forschungsergebnisse (vgl. Abb. 1). Datafied Scholarship als Kombination aus mehreren einzelnen Trends12 und nächste Stufe der DS führt dann zu einem Setting, in dem Forschung aller Disziplinen nicht nur auf komplexen Datensätzen basiert, sondern Forschungsergebnisse auch automatisch durchsucht und mittels Algorithmen individuell und auf Netzwerkebene ausgewertet werden können.13
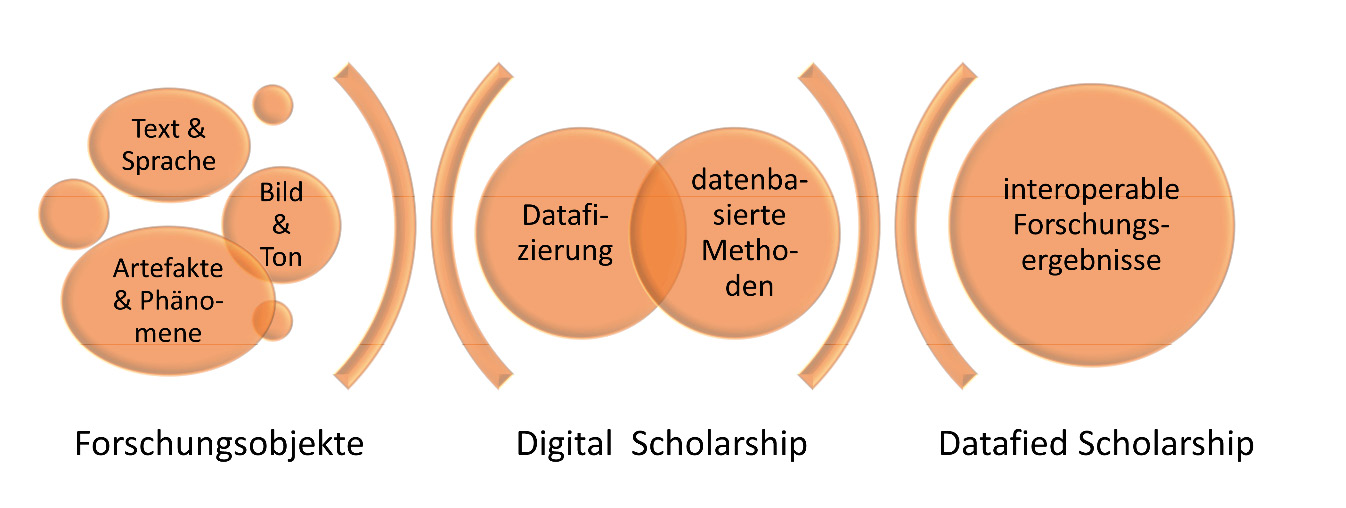
1.2 Voraussetzungen der Digital Scholarship
1.2.1 Datenbestände
Die Verfügbarkeit von Sprach- und Textbeständen ist nicht nur, aber in besonderem Maße für die Digital Humanities von zentraler Bedeutung.14 Die Analyse von großen Textbeständen bildet auch Grundlage für Verfahren in der Computational Social Science,15 z.B. bei der Untersuchung von Medieninhalten. Ebenso nutzen naturwissenschaftliche Disziplinen Textbestände, die in datafizierter Form zur Verfügung stehen, z.B. Wetterprognosen in Tageszeitungsarchiven. Von Schweizer Forschenden der Geistes- und Sozialwissenschaften werden als Daten-Desiderate neben solchen aus der Verwaltung insbesondere Daten aus Bibliotheken, Archiven und Museen benannt – letztere liegen jedoch oft nicht, oder nur in unzureichender Qualität vor. Eine hochwertige Verarbeitung, Strukturierung, Indexierung und Analyse der Textbestände ist explizit erwünscht, fehlt aber derzeit häufig.16 Der Zugang zu maschinenlesbaren, oder idealerweise maschinenverarbeitbaren17 Datenbeständen stellt somit disziplinübergreifend eine Voraussetzung für den Einsatz von datengetriebenen Methoden der DS dar.
Diese Entwicklung wurde von Kulturerbe-Institutionen18 mit der Formulierung des Collections-as-Data-Paradigmas aktiv aufgenommen. Das Santa Barbara Statement on Collections as Data19 führt zehn Prinzipien auf, um die computergestützte Nutzung von Beständen möglichst breit zu ermöglichen und zu fördern – im Kern also digitalisierte und born-digital Bestände datafiziert zur Verfügung zu stellen. Dies soll insbesondere mit einem „aim to lower barriers to use“20 und im Hinblick auf verschiedene Nutzergruppen geschehen. Konkret bedeutet dies, dass datafizierte Bestände in verschiedenen Verarbeitungsstufen (vgl. Abb. 2) und auf verschiedene Arten angeboten werden, etwa als Daten-Dumps zum Download in einfachen Formaten, über Anwendungsprogrammierschnittstellen (APIs) oder via Literate-Programming-Formaten wie Jupyter Notebooks.21

Dabei sollen ethische Überlegungen, Fragen der technischen Robustheit, Interoperabilität und Nachhaltigkeit adressiert werden und ausführliche Dokumentationen nicht nur Provenienz-Fragen transparent machen, sondern auch die Nutzung möglichst vereinfachen. Zugehörige Datenbestände wie Metadaten und Daten, die sich aus Analysen der Daten ergeben sollen ebenfalls zur Verfügung gestellt werden, und ebenso wie die Daten der Bestände möglichst „offen“, etwa unter freien Lizenzen, nutz- und verbreitbar sein.
1.2.2 Datentechnologien
Forschungsmethoden der DS sind datengetriebene Methoden. Text (and Data) Mining (TDM) als prominentes Beispiel kann als computergestützte Gewinnung neuer, bisher unbekannter Informationen durch die automatische Extraktion aus schriftlichen Quellen definiert werden.22 Grundlage von TDM bildet das Natural Language Processing (NLP), das die Vorverarbeitung und Analyse von Textdaten ermöglicht. Zum Einsatz kommen Verfahren, die Regeln, vor allem aber statistische Modelle nutzen, also Anwendungen der Data Science. Neben der Verarbeitung von Textdaten finden diese Verfahren ebenso Einsatz in der Analyse von Bilddaten, von numerischen und Netzwerkdaten. Dabei wird mit Data Science weit mehr gemeint als das eigentliche Training eines Modells, nämlich alle vor- und nachgelagerten Schritte und Methoden, die für ein valides Verfahren notwendig sind.23 Die herausragende Bedeutung, die Data-Science-Methoden aktuell erlangen, liegt darin, sehr große und komplexe Datenbestände auf komplexe Weise analysieren und neue Schlüsse ziehen zu können,24 etwa hochdimensionale Beziehungen in den Daten aufzudecken oder Vorhersagen zu treffen.
1.2.3 IT-Infrastrukturen
Die Analyse sehr großer und komplexer Datenbestände mit Data-Science-Methoden benötigt spezifische informationstechnologische Infrastrukturen. Mit Big Data werden Informationsgüter beschrieben, die sich durch ein so hohes Volumen, eine so hohe Geschwindigkeit und eine so große Vielfalt auszeichnen, dass spezifische Technologien und Analysemethoden für ihre Wertschöpfung erforderlich sind.25 Big-Data-fähige Infrastrukturen bieten spezifische Lösungen für Datensammlung, -haltung, -integration und -prozessierung,26 in der Regel in der Form von skalierbaren, verteilten Anwendungen. Die nötigen Rechenkapazitäten werden hierbei mittels High Performance Clustern (HPC) bzw. Cloud-Computing-Diensten akquiriert.
1.2.4 Digital Literacy
Datenbestände, Datentechnologien und IT-Infrastrukturen sind als Voraussetzungen für DS aufeinander bezogen und voneinander abhängig. Zur Anwendung von Data-Science-Methoden werden ausreichend große Datenmengen benötigt, für die Vorhaltung von großen Datenmengen und die Ausführung von Data-Science-Algorithmen wiederum spezifische IT-Infrastrukturen. DS erfordert somit Kompetenzen in mehreren, in sich komplexen und anspruchsvollen informations- und technologiebezogenen Feldern. Digital Literacy kann hier als Bindeglied für die Kenntnisse, Fertigkeiten und Fähigkeiten in diesen, zum Teil auch miteinander verwobenen, Feldern fungieren (vgl. Abb. 3).
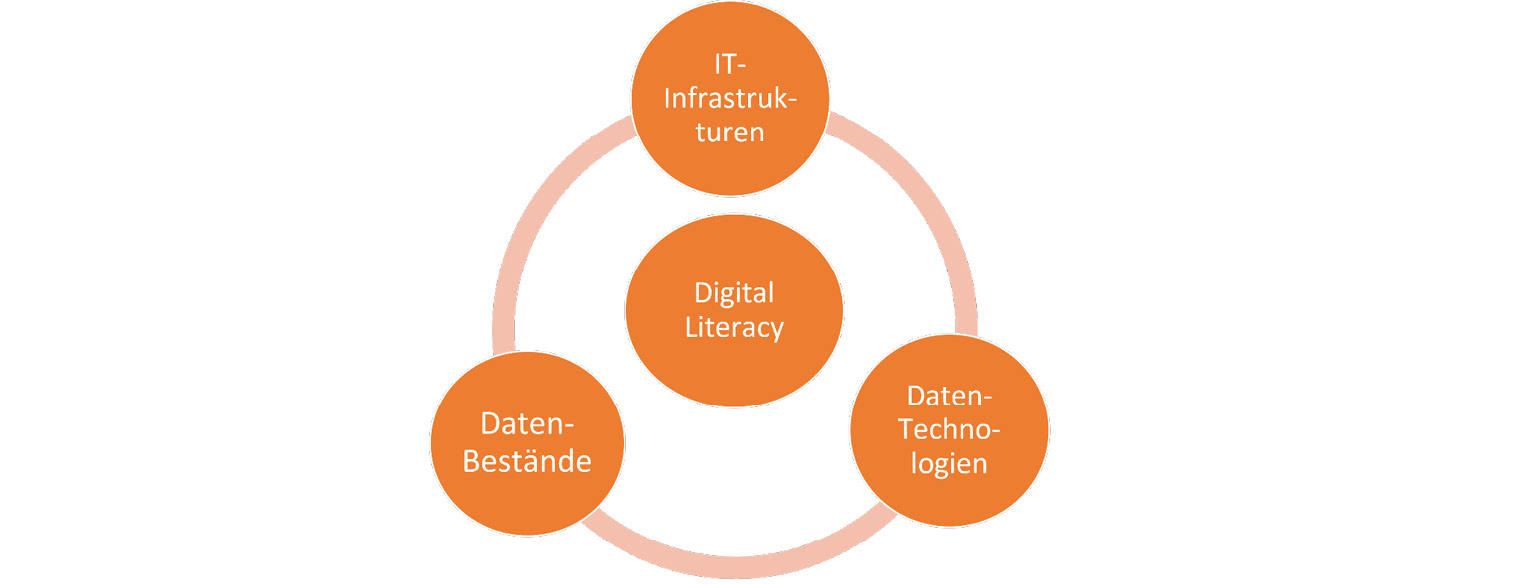
Digital Literacy kann in allgemeiner Form als Kompetenzfeld definiert werden, das Potential digitaler Werkzeuge nutzen zu können – in ihrer ganzen Tragweite, effizient, effektiv und ethisch – um Informationsbedürfnisse persönlicher und bürgerschaftlicher Art sowie im Berufsleben abzudecken.27 Die konkreten für die Ausübung von DS benötigten Digital Literacies werden durch Disziplin, Forschungsobjekt, -methodik und -ziel sowie weitere Faktoren bestimmt. Allerdings lassen sich im Zusammenhang mit DS dezidierte Kompetenzbereiche anführen, die übergreifende Bedeutung haben, wie praktische Computer Skills28, Computational Thinking29, Data Literacy30 und Algorithmic Literacy31.
2. Digital Scholarship Services
In wissenschaftlichen Bibliotheken etablieren sich aktuell Dienstleistungen und Angebote, die DS in Lehre und Forschung begleiten und unterstützen. Bibliothekarische Verbände haben hierzu Studien bzw. Empfehlungen herausgegeben32, betreiben entsprechende Sektionen oder Working Groups33, und vor allem größere wissenschaftliche Bibliotheken bieten mittlerweile ein typisches Dienstleistungsportfolio an.34
2.1 Berichte zur Entwicklung von Digital Scholarship Services
2.1.1 Der Digital-Scholarship-Bericht der Library of Congress
2020 veröffentlichte eine Arbeitsgruppe mit Vertretern aus mehreren Bereichen der US-amerikanischen Library of Congress (LoC) den Bericht Digital scholarship at the Library of Congress35 mit Empfehlungen für die Entwicklung von DS Services an der LoC. Ziel war die Klärung von Kundenbedürfnissen, abgeleitet von Kundenanfragen aus dem Jahr 201736 und die Formulierung von Maßnahmen. Anhand von Fallstudien wird im Report analysiert, wie sich die Verfügbarkeit der Sammlungen, die Fähigkeiten der Mitarbeitenden, und die bestehenden technischen Abläufe auf die Bearbeitung der Anfragen auswirkten. Zudem wurden Vertreter anderer Nationalbibliotheken interviewt, die bereits DS Services anboten37 und auf Erfahrungen der Association of Research Libraries (ARL) hinsichtlich Digital-Humanities- und Digital-Scholarship-Centern zurückgegriffen.38 Die Empfehlungen der Digital Scholarship Working Group umfassen drei große Bereiche, die nachfolgend vorgestellt werden.
A Maschinenlesbarkeit der Sammlungen priorisieren39
Der erste Abschnitt zielt zentral auf die Umsetzung des Collections-as-Data-Paradigmas: Digitale Bestände sollen maschinenlesbar („computational readiness“) und einfach zugänglich zur Verfügung gestellt werden. Dies können gemäß verschiedenen Nutzungsszenarien z.B. vorpaketierte Metadaten, Bilddateien, Rohdaten aus der Texterkennung, Tabellendaten oder Code sein, die über Bulk Downloads und APIs zur Verfügung gestellt werden.40 Grundlage hierfür sind ein extensiver Ausbau der Retrodigitalisierung, entsprechende Abklärungen im Bereich der Urheber- und Persönlichkeitsrechte und eine stete Optimierung hinsichtlich der technischen Umsetzung.
B Kompetenzen für Digital Scholarship in der Institution aufbauen41
Der zweite Bereich betrifft das Personal der LoC und seine Kompetenzen. Hier soll ein generelles Verständnis hinsichtlich der Bedarfe der DS und der dafür nötigen Entwicklungen in der Bibliothek geschaffen werden. Über die LoC hinweg sollen Kompetenzen, ethische Rahmenbedingungen und Praxen für einen besseren DS Support entwickelt werden. Als zentrale Maßnahme wird eine konzertierte Anstrengung zur Schaffung einer Community of Practice empfohlen.
C Nutzerorientierte Dienstleistungen ausbauen42
In vorausschauender Weise bezieht sich der dritte Abschnitt der Empfehlungen auf die mittelfristige Entwicklung von weiteren DS Services für verschiedene Nutzergruppen. Hierfür sind allerdings weitere Investitionen nötig. Zu den Dienstleistungen gehören die Beantwortung von technischen und allgemeinen Fragen, die Unterstützung bei Forschungsprojekten und die Kompetenzvermittlung durch formale Schulungen und informelle Beratungen. Die Mitarbeitenden wären auch für die Entwicklung von Arbeitsabläufen, Technologien und Werkzeugen zuständig, die zur Datenbereitstellung und Nutzung der Sammlungen nötig sind.
Der Bericht schließt mit der Einordnung, dass Digital Scholarship Services eine natürliche und unvermeidliche Weiterführung der Sammlungsarbeit der LoC darstellen und die Bibliothek als immer wichtiger werdende Ressource im 21. Jahrhundert positionieren.43
2.1.2 Der Lippincott-Bericht zu neuen Technologien in wissenschaftlichen Bibliotheken
Der Report Mapping the current landscape of research library engagement with emergent technologies in research and learning wurde 2020 von Sarah Lippincott verfasst und durch mehrere Non-Profit-Organisationen des Informationssektors veröffentlicht. In einem 5-Jahres-Horizont erläutert der umfassende Bericht die strategischen Möglichkeiten, die sich für wissenschaftliche Bibliotheken durch neue Technologien bieten. Grundlage hierfür bildeten eine Literaturrecherche über Publikationen der vorherigen fünf Jahre und Interviews mit einer Reihe von Bibliotheksexperten. Der Report behandelt in sieben Teilberichten vier Querschnittsthemen und fünf Hauptaufgabenfelder für Bibliotheken. Im Folgenden wird nur auf den Teilbericht Advancing digital scholarship (2020)44 rekurriert, wobei für Sarah Lippincott Digital Scholarship Services im Kern Unterstützungsleistungen für datengetriebene Vorhaben sind.45
Auch Lippincott gliedert ihre Beobachtungen und Schlussfolgerungen in drei Bereiche. Im Vergleich zum LoC-Report legt sie jedoch stärkeren Fokus auf die Erfordernisse von Data Science, Big Data und Forschungsdaten.
A Dienste entwickeln, die verschiedenen Daten in allen Disziplinen gerecht werden46
Die Nachfrage nach Daten für DS führt dazu, dass Bibliotheken Datenkonvolute und TDM-Lizenzen erwerben, rechtliche Beratungen hierzu anbieten und Zugänge zu Daten kuratieren. Allerdings geschieht dies oft nur auf einen konkreten Wunsch hin. Die Entwicklung von systematischen Sammlungsprozessen analog zu anderen Bestandssegmenten steht dagegen in der Regel noch aus.47
Aktuelle Forschungsdatenservices fokussieren sich oft auf die Publikation und Archivierung gemäß Vorgaben von Förderern und Verlagen. Dabei gerät aus dem Blick, dass komplexe Daten zum Teil kaum mehr trennbar sind von den Algorithmen und IT-Umgebungen, mit denen sie erstellt und verarbeitet werden. Für kundenorientierte Datenservices ist ein Paradigmenwechsel nötig von singulären, fixen Datenentitäten hin zu einem volatilen Forschungsdaten-Begriff („recognize data as a living asset”).48
Es ist damit nicht nur nötig, Infrastrukturen zu entwickeln, die kollaborative Datennutzung, Nachnutzung und Langzeitarchivierung ermöglichen. Ebenso sollten Technologien zur gemeinsamen Paketierung von Daten, Analyse-Code und IT-Umgebung integriert werden, gerade im Hinblick auf die Reproduzierbarkeit von Ergebnissen. Die Nutzung von großen Rechenkapazitäten und Big-Data-Anwendungen erfordert Absprachen mit Rechenzentren, institutionenübergreifende Kooperation und befördert zudem die Nutzung von Cloud-Computing-Diensten.49
B Maschinenverarbeitbare Sammlungen bereitstellen und pflegen50
Lippincott betont die zentrale Rolle, die Collections as Data und begleitende Dienstleistungen wie Workshops, Beratungen, digitale Plattformen für Forschende spielen – insbesondere sind qualitativ hochstehende Bibliotheksdaten für Machine-Learning- und Deep-Learning-Methoden sehr interessant. Collections as Data kann hier allerdings auch erhebliche rechtliche, technische, ethische und politische Implikationen mit sich bringen, gerade wenn ältere, möglicherweise vorurteilsbehaftete Daten eingesetzt werden.51
C Schulung und Beratung in Data Science anbieten52
Nach Lippincott sind es der Aufschwung von datengetriebener Forschung und die damit notwendigen Skills, die zu forschungsbegleitenden, beratenden und kompetenzvermittelnden Services und Strukturen in Bibliotheken geradezu auffordern – und zwar disziplinübergreifend.53
Insbesondere Angehörige der Geistes- und Sozialwissenschaften profitieren von basalen Angeboten zu Datenkompetenzen und Daten-Infrastrukturen. Neben üblichen Formaten können hier projekt- und lab-basierte Modelle die Basis für längere Partnerschaften bilden. Schließlich wird als kritischer Faktor die entsprechende Qualifizierung des eigenen Personals genannt, da Rekrutierungen im Data-Science-Bereich oft schwerfällig verlaufen.
Zusammengefasst sieht Sarah Lippincott, mit Verweis auf mehrere Interviews, in Digital Scholarship Services enorme strategische Chancen für Bibliotheken (“myriad strategic opportunities”) im Aufgabenfeld der Datenkuratierung und den damit zusammenhängenden Services, Infrastrukturen und der Vermittlung von entsprechenden Kompetenzen.54
2.2 Digital Scholarship Services: Fazit
DS und die damit verbundenen vielgestaltigen Herausforderungen technologischer, infrastruktureller und intellektueller Art umfasst alle Disziplinen. Wenngleich Bibliotheken im Feld der Forschungsunterstützung nicht allein Verantwortung übernehmen können und sollen, sind sie durch ihre angestammten Dienste unmittelbar angesprochen.
Ganz offensichtlich ist das der Fall bei der Bereitstellung von Collections as Data. Aufbereitung, Kuratierung und Publikation von eigenen und erworbenen Beständen als Forschungsdaten funktionieren allerdings nicht ohne Voraussetzungen. Für diese neue Aufgabe werden spezifische Kompetenzen, Ressourcen und Infrastrukturen benötigt, v.a. solche der Data Science und des Data Engineerings. Je nach Beständen und Vorhaben sind spezifische Skills nötig, etwa Kenntnisse in der Computer Vision oder im NLP. Größere und komplexe Datenbestände können zudem oft nicht einfach als Dump bereitgestellt werden. Sie benötigen spezifische Daten- und Infrastrukturen, die Big Data gerecht werden.
Nimmt man diese Punkte ernst, verwundert es nicht, wenn Sarah Ames und Stuart Lewis (2020)55 hier von einem „computational turn in heritage“56 und einem Paradigmenwechsel in Kulturerbeinstitutionen sprechen. Collections as Data birgt mithin nicht nur tiefgreifende Implikationen für viele Bibliotheksbereiche, es berührt das Konzept von Sammlungen an sich und damit auch das Selbstverständnis von Bibliotheken im Sinne von „future heritage makers“.57
Mit der Ausrichtung auf die Unterstützung von datengetriebener Forschung entsteht gleichsam ein großer Bedarf an vermittelnden Dienstleistungen: Konkret etwa zur Nutzung von neuen technologischen Angeboten und Produkten wie Daten-APIs und TDM-Plattformen,58 aber auch grundsätzlich in Bezug auf basale und spezifische Angebote zur Förderung von Digital Literacy. Datenkompetenzen und Computer Skills sind Schlüsselkompetenzen von allgemeiner Bedeutung, ebnen aber auch ganz praktisch den Weg für DS. Primäre Zielgruppen sind hier sowohl Studierende als auch Forschende, in deren Ausbildung etwa datengetriebene Forschungsmethoden noch keine Rolle spielten. Die aktive Förderung von Digital Literacy ist daher ein weiterer zentraler Aufgabenbereich von Digital Scholarship Services – wie in basaler Form von Bibliotheken generell.59
3. Entwicklung von Digital Scholarship Services an der UB Bern
3.1 Hintergrund und Konzeption
Die Universitätsbibliothek Bern (UB Bern) entwickelt seit Februar 2020 im Rahmen der universitären Digitalisierungsstrategie ihre Digital Scholarship Services. Vorangegangen waren hierzu zwei Bottom-up-Prozesse: Einerseits die Gründung einer abteilungsübergreifenden Arbeitsgruppe Digitale Dienste, um mittels Literaturrecherche, Diskussionen und Interviews mit Forschenden die Weiterentwicklung der Digitalen Dienste voranzutreiben. Zum anderen die Gründungen von zwei Hands-On-Gruppen, von denen eine sich mit der Programmierung mit Python und Machine Learning befasste, und die andere mit Linked Open Data. Nach einem Zwischenbericht (2018) der Arbeitsgruppe wurde 2019 das interne Arbeitspapier Digital Scholarship an der UB Bern60 durch die Co-Leitung des Bereichs Digitale Dienste & Open Science konsolidiert. Daraufhin konnte eine Projektstelle für eine DS Spezialistin geschaffen werden, die im Februar 2020 besetzt wurde.
Durch sie erfolgte die umfassende Konzipierung des Bereichs Digital Scholarship Services. Neben Literaturrecherche und Umfeldanalyse wurden Gespräche mit Ansprechpersonen von Fakultäten, den Digital Humanities, dem Vizerektorat Lehre und einigen UB-internen Stellen wie dem Zentrum Historische Bestände, Digitalisierung und Fachreferaten geführt. Ebenfalls wurden Umfragen zu forschungsunterstützenden Services aus drei Bibliotheksbereichen einbezogen. Im Juni 2020 konnte der Geschäftsleitung UB Bern ein Basis-Papier61 vorgelegt werden: Neben der Klärung des Arbeitsgebietes wurden zentrale Ansatzpunkte für Aktionsfelder und Bedingungen hinsichtlich Kompetenzentwicklung, Ressourcen und Organisation ausgeführt. Bei der Erstellung wurden insbesondere die oben besprochenen Empfehlungen der LoC von Harris u.a. (2020) berücksichtigt.62
Nach einem positiven Bescheid wurde eine Konkretisierung mit Priorisierung von Maßnahmen und Ressourcenabschätzung beauftragt und diese63 im Oktober 2020 vorgelegt. Die Empfehlungen sind in vier Aktionsfelder gegliedert, wobei die folgenden zwei Aktionsfelder für die kurz- bis mittelfristige Umsetzung priorisiert wurden:
Aktionsfeld Collections as Data & Data Collections
- konsolidierte Bereitstellung von Datenkonvoluten auf der UB Website
- Aufbau einer state-of-the-art Präsentationsplattform für eigene Digitalisate
Aktionsfeld Digital Literacy: Data Literacy & Computer Skills
- Entwicklung von niedrigschwelligen Vermittlungsangeboten zur Digital Literacy (Datenkompetenzen und begleitende Computer Skills).
3.2 Aktuelles Service-Angebot
Nachfolgend werden die abgeschlossenen und aktuellen Umsetzungen in den priorisierten Aktionsfeldern vorgestellt. Danach wird eine erste Einschätzung zu Nutzung und Resonanz der Services gegeben.
3.2.1 Collections as Data & Data Collections
Ziel: Generische und spezifische Zugänge zu Datenkonvoluten schaffen.
Umsetzung 1: Bereitstellung eigener, lizenzierter und freier Datenressourcen.
- Erstellung von Datenzugängen zu Beständen auf den Plattformen e-rara64, e-manuscripta65 und e-periodica66 mittels Jupyter Notebooks67
- Abklärung von rechtlichen und technischen Bedingungen zur Datennutzung von
- Lizenzierung und Einführung von zwei TDM-Plattformen
- Erstellung eines Volltextkorpus aus wissenschaftlicher Literatur on demand
Umsetzung 2: Entwicklung des Webauftritts der Digital Scholarship Services71 mit konsolidierten Informationen zu Ressourcen und Services.
3.2.2 Digital Literacy: Data Literacy & Computer Skills
Ziel: Schlüsselkompetenzen im Umgang mit Daten, Methoden und Tools fördern.
Umsetzung 1: synchrones Vermittlungsangebot: Schulungen vor Ort und online/hybrid
- für Nutzende
- für UB-Mitarbeitende (Details vgl. Tab. 1).
Umsetzung 2: asynchrones Vermittlungsangebot in Form von Tutorials, in Zusammenarbeit mit Fachreferaten
- DS Python Toolbox als wachsendes Angebot an Jupyter Notebooks für die Datenarbeit mit Textdokumenten und APIs.72
3.2.3 Erfahrungen
Die Umsetzungen in beiden Aktionsfeldern wurden positiv aufgenommen. Die Digital-Literacy-Angebote für verschiedene Zielgruppen konnten gute Teilnehmerzahlen erzielen, Tabelle 1 gibt einen Überblick über die bisherigen Anlässe 2021 bis Oktober 2022.
|
Zielgruppe |
Teilneh- |
Anlass |
Themen |
|
Forschende |
60 |
6 Coffee Lectures bzw. Präsentationen |
verschiedene: Einführung in das TDM, Harvesting mit APIs, Nutzung von TDM-Plattformen |
|
Doktorierende |
19 |
Präsentation/Workshop im Programm |
Data Cleaning with Python |
|
Peers, intern |
24 |
2 Workshops für Mitarbeitende der UB Bern |
OpenRefine |
|
Peers, extern |
12 |
Workshop für Mitglieder der IGWBS73 |
Jupyter/Python, Nutzung |
|
Peers, extern |
14 |
Modul im CAS Datenmanagement und |
Digital Scholarship |
Eine gute Resonanz lässt sich ebenso für die Website der DS Services feststellen. Tabelle 2 gibt einen Eindruck zur Entwicklung der Zugriffszahlen auf die initiale Webpage zu TDM-Ressourcen ab September 2021 sowie zur umfassenden Digital-Scholarship-Website (deutsch, mit Unterseiten) ab Mai 2022.
|
Zeitraum |
Seitenaufrufe |
Besuche |
|
|
Webpage TDM |
Sept. – Dez. 2021 |
252 |
210 |
|
Webpage TDM |
Jan. – April 2022 |
209 |
170 |
|
Website DS Services |
Mai – Aug. 2022 |
1360 |
530 |
Positive Rückmeldungen hinsichtlich der Verfügbarmachung von Datenbeständen gab es insbesondere für den Datenzugang zu eigenen und nationalen Beständen75, die Lizenzierung von TDM-Plattformen76 und die Erstellung eines Volltextkorpus aus wissenschaftlicher Literatur für ein Forschungsprojekt. Die Erfahrungen an der UB Bern zeigen aber auch, dass Bestände als Daten für die Forschung nutzbar zu machen keine triviale, sondern durchaus eine zeitaufwändige Aufgabe ist. Neben den Auftrag, die eigenen Bestände zukunftsorientiert zur Verfügung zu stellen, tritt daher ein weiteres Argument: Forschungsunterstützende Services setzen am besten dort an, wo Bibliotheken Forschende von Aufgaben direkt entlasten können. Mit der nutzerorientierten Dokumentation von Daten-Schnittstellen, der Bereitstellung und Erstellung von Datenkonvoluten legen Bibliotheken den Grundstein für sehr geschätzte Dienstleistungen.
4. Fazit
Das Konzept Digital Scholarship dient der Theoriebildung zur digitalen Transformation der Wissenschaft. Mit der Analyse von zentralen Voraussetzungen der DS können gleichsam Herausforderungen und Chancen von wissenschaftlichen Bibliotheken im Umgang mit datengetriebenen Forschungsansätzen eruiert werden. Digital Scholarship Services bieten einen vielversprechenden Ansatz, um zukunftsorientierte forschungsunterstützende Services zu entwickeln. Collections as Data im Besonderen stellen eine unverzichtbare Grundlage für datengetriebene Methoden, insbesondere in den Geistes- und Sozialwissenschaften, dar und bergen gleichzeitig disruptives Potential für Bibliotheken. Mit der Kuration und Aufbereitung von Beständen als Datenkonvolute kann die Verfügbarkeit von Forschungsdaten in entscheidendem Umfang erhöht werden. Für wissenschaftliche Bibliotheken stellt dies – neben der begleitenden aktiven Förderung von Digitalkompetenzen – eine große Chance zur adäquaten Positionierung in der durch die digitale Transformation geprägten Forschungswelt dar.
Literaturverzeichnis
- Alemneh, Daniel Gelaw; Hartman, Cathy Nelson; Hastings, Samantha Kelly: Meeting the Demands of Digital Scholarship: Challenges and Opportunities, in: Proceedings of the
American Society for Information Science and Technology 42 (1), 2005. Online: <https://doi.org/10.1002/meet.14504201255>. - Ames, Sarah; Lewis, Stuart: Disrupting the Library: Digital Scholarship and Big Data at the National Library of Scotland, in: Big Data & Society 7 (2), 2020. <https://doi.org/10.1177/
2053951720970576>. - Borgman, Christine L.: Big Data, Little Data, No Data: Scholarship in the Networked World, 2015. Online: <https://www.jstor.org/stable/j.ctt17kk8n8>, Stand: 24.09.2021.
- Borgman, Christine L.: Scholarship in the Digital Age: Information, Infrastructure, and the Internet, Cambridge, MA 2007.
- Bubenhofer, Noah; Rothenhäusler, Klaus: „Korporatheken“. Die digitale und verdatete
Bibliothek, in: 027.7 Zeitschrift für Bibliothekskultur / Journal for Library Culture 4 (2), 2016, S. 60–71. <https://doi.org/10.5281/zenodo.4705307>. - Candela, Gustavo; Sáez, María Dolores; Escobar Esteban, MPilar u.a.: Reusing Digital Collections From GLAM Institutions, in: Journal of Information Science 48 (2), 2022, S. 251–267. Online: <https://doi.org/10.1177/0165551520950246>.
- De Mauro, Andrea; Greco, Marco; Grimaldi, Michele: What is Big Data? A Consensual Definition and a Review of Key Research Topics, in: AIP Conference Proceedings 1644 (1), 09.02.2015, S. 97–104. <https://doi.org/10.1063/1.4907823>.
- Ebeling, Johanna; Koch, Henning; Roth-Grigori, Alexander (Hg.): Kompetenzerwerb im kritischen Umgang mit Daten: Data Literacy Education an deutschen Hochschulen, Essen 2021. Online: <https://www.stifterverband.org/medien/kompetenzerwerb-im-kritischen-umgang-mit-daten>, Stand: 13.06.2022.
- Fritz, Nele: Digital Scholarship und deutsche Universitätsbibliotheken: Entwicklungsstand und Vergleich zu ausgewählten US-amerikanischen Bibliotheken, Bachelorarbeit, TH Köln, 2017. Online: <https://nbn-resolving.org/urn:nbn:de:hbz:79pbc-opus-9959>.
- Gebru, Timnit; Morgenstern, Jamie; Vecchione, Briana u. a.: Datasheets for Datasets, in: arXiv:1803.09010 [cs], 19.03.2020. Online: <http://arxiv.org/abs/1803.09010>, Stand: 21.02.2021.
- Greenhall, Matt: Digital Scholarship and the Role of the Research Library. RLUK Report, Research Libraries UK, 07.2019. <https://www.rluk.ac.uk/digital-scholarship-and-the-role-of-the-research-library-an-rluk-report/>, Stand: 07.10.2022.
- Harris, Grant; Potter, Abigail; Zwaard, Kate u.a.: Digital Scholarship at the Library of Congress: User Demand, Current Practices, and Options for Expanded Services, Library of Congress, 17.03.2020. Online: <https://labs.loc.gov/static/labs/work/reports/DHWorkingGroupPaper-v1.0.pdf>.
- Harvard University Digital Scholarship Support Group (DSSG): Digital Scholarship at Harvard:
The First Four Years of the Digital Scholarship Support Group, Harvard University, 2019. Online:
<https://dssg.fas.harvard.edu/wp-content/uploads/2019/09/PUBLIC_REPORT_FINAL_
2019.pdf>, Stand: 22.05.2020. - Hauf, Nicolai; Fürholz, Andreas; Klaas, Vanessa Christina u.a.: Data Reuse in the Social Sciences
and Humanities: Project Report of the SWITCH Innovation Lab “Repositories & Data Quality”, ZHAW Zurich University of Applied Sciences with support from SWITCH, Winterthur 03.2021, S. 19–20, 25. <https://doi.org/10.21256/zhaw-2404>. - Hearst, Marti: What is Text Mining?, 17.10.2003, <https://people.ischool.berkeleyedu/~hearst/
text-mining.html>, Stand: 07.07.2022. - Heidrich, Jens; Bauer, Pascal; Krupka, Daniel: Future Skills: Ansätze zur Vermittlung von Data Literacy in der Hochschulbildung, Arbeitspapier 37, Hochschulforum Digitalisierung, Berlin 2018. Online: <https://doi.org/10.5281/zenodo.1413119>.
- Hervieux, Sandy; Wheatley, Amanda (Hg.): The Rise of AI: Implications and Applications of Artificial Intelligence in Academic Libraries, Chicago, Ill. 2022 (ACRL Publications in Librarianship 78).
- Ignatow, Gabe; Mihalcea, Rada: Text Mining: A Guidebook for the Social Sciences, Thousand Oaks 2017. Online: <https://doi.org/10.4135/9781483399782>.
- International Federation of Library Associations and Institutions (IFLA): IFLA Statement on Digital Literacy, 18 August 2017, International Federation of Library Associations and Institutions (IFLA), 18.08.2017. Online: <https://repository.ifla.org/handle/123456789/1283>.
- Kotu, Vijay; Deshpande, Bala: Data Science: Concepts and Practice, Cambridge, MA 2019. Online: <https://doi.org/10.1016/C2017-0-02113-4>.
- Lippincott, Sarah: Mapping the Current Landscape of Research Library Engagement With Emerging Technologies in Research and Learning: Advancing Digital Scholarship, Association of Research Libraries, Born-Digital, Coalition for Networked Information, and EDUCAUSE, 06.07.2020. <https://doi.org/10.29242/report.emergingtech2020.landscape>.
- Mackenzie, Alison; Martin, Lindsey (Hg.): Developing Digital Scholarship: Emerging Practices in Academic Libraries, 2016. Online: <https://doi.org/10.29085/9781783301799>.
- Oliver, Jeffrey C.; Kollen, Christine; Hickson, Benjamin u.a.: Data Science Support at the Academic Library, in: Journal of Library Administration 59 (3), 2019, S. 241–257. Online: <https://doi.org/10.1080/01930826.2019.1583015>.
- Padilla, Thomas; Allen, Laurie; Frost, Hannah u.a.: Santa Barbara Statement on Collections as Data – Always Already Computational: Collections as Data (Version 2), 20.05.2019. <https://doi.org/10.5281/zenodo.3066209>.
- Pearce, N.; Weller, M.; Scanlon, E. u.a.: Digital Scholarship Considered: How New Technologies Could Transform Academic Work, in: In Education 16 (1), 2010, S. 33–44. Online: <http://dx.doi.org/10.37119/ojs2010.v16i1.44>.
- Pinfield, S.; Cox, A.; Rutter, S.: Mapping the Future of Academic Libraries: A Report for SCONUL, Society of College, National and University Libraries (SCONUL), London 11.12.2017. <https://sconul.ac.uk/publication/mapping-the-future-of-academic-libraries>, Stand: 23.08.2022.
- Prudlo, Marion: Digital Scholarship an der UB Bern, Universitätsbibliothek Bern, 10.2019. Unveröffentlicht.
- Ridley, Michael; Pawlick-Potts, Danica: Algorithmic Literacy and the Role for Libraries, in: Information Technology and Libraries 40 (2), 2021. <https://doi.org/10.6017/ital.v40i2.12963>.
- Roemer, Robin Chin; Kern, Verletta (Hg.): The Culture of Digital Scholarship in Academic Libraries, Chicago 2019.
- Romein, C. Annemieke; Kemman, Max; Birkholz, Julie M. u.a.: State of the Field: Digital History, in: History 105 (365), 2020, S. 291–312. Online: <https://doi.org/10.1111/1468-229X.12969>.
- Schöch, Christof: Big? Smart? Clean? Messy? Data in the Humanities, in: Journal of Digital Humanities 2 (3), 2013, S. 2–13. Online: <http://journalofdigitalhumanities.org/2-3/big-smart-clean-messy-data-in-the-humanities/>, Stand: 21.06.2022.
- Senseney, Megan; Dickson Koehl, Eleanor; Sandore Namachchivaya, Beth u.a.: Transforming Library Services for Computational Research With Text Data: Environmental Scan, Stakeholder Perspectives, and Recommendations for Libraries, Association of College and Research Libraries, Chicago, Ill, 2021. Online: <https://acrl.ala.org/acrlinsider/transforming-library-
services-for-computational-research-with-text-data-environmental-scan-stakeholder-
perspectives-and-recommendations-for-libraries/>, Stand: 25.08.2021. - Vinopal, Jennifer; McCormick, Monica: Supporting Digital Scholarship in Research Libraries: Scalability and Sustainability, in: Journal of Library Administration 53 (1), S. 27–42. Online: <https://doi.org/10.1080/01930826.2013.756689>.
- Wilkinson, Mark D.; Dumontier, Michel; Aalbersberg, IJsbrand Jan u.a.: The FAIR Guiding Principles for Scientific Data Management and Stewardship, in: Scientific Data 3 (1), 15.03.2016, S. 4. <https://doi.org/10.1038/sdata.2016.18>.
- Wilms, Lotte: Digital Humanities in European Research Libraries. Beyond Offering Digital Collections, in: LIBER Quarterly 31 (1), 2021, S. 1–23. Online: <https://doi.org/10.18352/lq.10351>.
- Woitas, Kathi: Digital Scholarship Services – Neue Dienstleistungen von wissenschaftlichen Bibliotheken für die datenbasierte Forschung, in: 110. Deutscher Bibliothekartag in Leipzig 2022 = 8. Bibliothekskongress, Leipzig 2022. <https://nbn-resolving.org/urn:nbn:de:0290-opus4-179091>.
- Woitas, Kathi: Digital Scholarship Services an der Universitätsbibliothek Bern: Umsetzung, Universitätsbibliothek Bern, 07.10.2020. Unveröffentlicht.
- Woitas, Kathi: Digital Scholarship Services an der Universitätsbibliothek Bern, Universitätsbibliothek Bern, 15.06.2020. Unveröffentlicht.
1 Dieser Beitrag ist die bearbeitete Fassung eines Vortrags im Rahmen des 8. Bibliothekskongresses 2022. Die Vortragsfolien sind veröffentlicht: Woitas, Kathi: Digital Scholarship Services – Neue Dienstleistungen von wissenschaftlichen Bibliotheken für die datenbasierte Forschung, in: 110. Deutscher Bibliothekartag in Leipzig 2022 =
8. Bibliothekskongress, Leipzig 2022. <https://nbn-resolving.org/urn:nbn:de:0290-opus4-179091>.
2 Vgl. etwa Alemneh, Daniel Gelaw; Hartman, Cathy Nelson; Hastings, Samantha Kelly: Meeting the Demands of Digital Scholarship: Challenges and Opportunities, in: Proceedings of the American Society for Information Science and Technology 42 (1), 2005. Online: <https://doi.org/10.1002/meet.14504201255>; Pearce, N.; Weller, M.; Scanlon,
E. u.a.: Digital Scholarship Considered: How New Technologies Could Transform Academic Work, in: In Education 16 (1), 2010, S. 33–44. Online: <http://dx.doi.org/10.37119/ojs2010.v16i1.44>; Vinopal, Jennifer; McCormick, Monica: Supporting Digital Scholarship in Research Libraries: Scalability and Sustainability, in: Journal of Library Administration 53 (1), S. 27–42. Online: <https://doi.org/10.1080/01930826.2013.756689>; Mackenzie, Alison; Martin, Lindsey (Hg.): Developing Digital Scholarship: Emerging Practices in Academic Libraries, 2016. Online: <https://doi.org/10.29085/9781783301799>; Fritz, Nele: Digital Scholarship und deutsche Universitätsbibliotheken: Entwicklungsstand und Vergleich zu ausgewählten US-amerikanischen Bibliotheken, Bachelorarbeit, TH Köln, 2017. Online: <https://nbn-resolving.org/urn:nbn:de:hbz:79pbc-opus-9959>; Roemer, Robin Chin; Kern, Verletta (Hg.): The Culture of Digital Scholarship in Academic Libraries, Chicago 2019; Harvard University Digital Scholarship Support Group (DSSG): Digital Scholarship at Harvard: The First Four Years of the Digital Scholarship Support Group, Harvard University, 2019. Online: <https://dssg.fas.harvard.edu/wp-content/uploads/2019/09/PUBLIC_REPORT_FINAL_2019.pdf>, Stand: 22.05.2020.
3 Borgman, Christine L.: Scholarship in the Digital Age: Information, Infrastructure, and the Internet, Cambridge, MA 2007, S. xvii.
4 Ebd., S. 115–148.
5 Borgman, Christine L.: Big Data, Little Data, No Data: Scholarship in the Networked World, 2015. Online: <https://www.jstor.org/stable/j.ctt17kk8n8>, Stand: 24.09.2021.
6 Ebd., S. 31–32.
7 Ebd., S. 52.
8 Zu den verwandten Begriffen von Digital Scholarship und Digital Humanities stellt Matt Greenhall mit Blick auf Arbeitsdefinitionen in britischen Bibliotheken fest, dass DS das Gebiet der Digital Humanities beinhaltet, darüber hinaus aber weitere Disziplinen umfasst. Vgl. Greenhall, Matt: Digital Scholarship and the Role of the Research
Library. RLUK Report, Research Libraries UK, 2019. S. 10. <https://www.rluk.ac.uk/digital-scholarship-and-the-role-of-the-research-library-an-rluk-report/>, Stand: 07.10.2022.
9 Romein, C. Annemieke; Kemman, Max; Birkholz, Julie M. u.a.: State of the Field: Digital History, in: History 105 (365), 2020, S. 291–312. Online: <https://doi.org/10.1111/1468-229X.12969>.
10 Ebd., S. 307–311.
11 Senseney, Megan; Dickson Koehl, Eleanor; Sandore Namachchivaya, Beth u.a.: Transforming Library Services for Computational Research With Text Data: Environmental Scan, Stakeholder Perspectives, and Recommendations for Libraries, Association of College and Research Libraries, Chicago, Ill.,.2021, S. 43. Online: <https://acrl.ala.org/
acrlinsider/transforming-library-services-for-computational-research-with-text-data-environmental-scan-stakeholder-
perspectives-and-recommendations-for-libraries/>, Stand: 25.08.2021.
12 Pinfield u.a. (2017) zählen hierzu Open Access, Open Science, Text and Data Mining, Artificial Intelligence und Machine Learning, Internet of Things, Digital Humanities und akademische soziale Netzwerke. Vgl. Pinfield, S.; Cox, A.; Rutter, S.: Mapping the Future of Academic Libraries: A Report for SCONUL, Society of College, National and University Libraries (SCONUL), London 11.12.2017, S. 16. <https://sconul.ac.uk/publication/mapping-the-future-of-academic-libraries>, Stand: 23.08.2022.
13 Ebd.
14 Schöch, Christof: Big? Smart? Clean? Messy? Data in the Humanities, in: Journal of Digital Humanities 2 (3), 2013, S. 2–13. Online: <http://journalofdigitalhumanities.org/2-3/big-smart-clean-messy-data-in-the-humanities/>, Stand: 21.06.2022. Bubenhofer, Noah; Rothenhäusler, Klaus: „Korporatheken“. Die digitale und verdatete Bibliothek, in: 027.7 Zeitschrift für Bibliothekskultur / Journal for Library Culture 4 (2), 2016, S. 60–71. <https://doi.org/10.5281/zenodo.4705307>.
15 Siehe z.B. Ignatow, Gabe; Mihalcea, Rada: Text Mining: A Guidebook for the Social Sciences, Thousand Oaks 2017. Online: <https://doi.org/10.4135/9781483399782>.
16 Hauf, Nicolai; Fürholz, Andreas; Klaas, Vanessa Christina u.a.: Data Reuse in the Social Sciences and Humanities: Project Report of the SWITCH Innovation Lab “Repositories & Data Quality”, ZHAW Zurich University of Applied Sciences with support from SWITCH, Winterthur 03.2021, S. 19–20, 25. <https://doi.org/10.21256/zhaw-2404>.
17 Als deutsche Übersetzung zum englischen Begriff „machine-actionable“ wird „Maschinenverarbeitbarkeit“ verwendet. Dieses Konzept ist zentral für Umsetzungen des Semantic Webs wie der FAIR-Prinzipien von Forschungsdaten. Gemeint sind Umsetzungen, die eine selbsterklärende Nutzung der Ressourcen durch Maschinen erlauben. Wilkinson u.a. (2016) unterscheiden hier „data that is machine-actionable as a result of specific investment in software supporting that data-type […], and data that is machine-actionable exclusively through the utilization of general-purpose, open technologies“. Vgl. Wilkinson, Mark D.; Dumontier, Michel; Aalbersberg, IJsbrand Jan u.a.: The FAIR Guiding Principles for Scientific Data Management and Stewardship, in: Scientific Data 3 (1), 15.03.2016, S. 4. <https://doi.org/10.1038/sdata.2016.18>.
18 Das Projekt Collections as Data: Always Already Computational wurde 2016 vom Institute of Museum and Library Services initiiert und community-basiert in Form von mehreren Workshops vorangetrieben, siehe die Projektseite <https://collectionsasdata.github.io/> bzw. dessen Fortführung Collections as Data: Part to Whole, <https://collectionsasdata.github.io/part2whole/>, finanziert durch die The Andrew W. Mellon Foundation.
19 Padilla, Thomas; Allen, Laurie; Frost, Hannah u.a.: Santa Barbara Statement on Collections as Data – Always Already Computational: Collections as Data (Version 2), 20.05.2019. <https://doi.org/10.5281/zenodo.3066209>.
20 Ebd., S. 3.
21 Eine Methodologie und Beispiele zur Bereitstellung von maschinenverarbeiten Daten aus Bibliotheken und ähnlichen Institutionen bieten Candela u.a. (2022), Candela, Gustavo; Sáez, María Dolores; Escobar Esteban, MPilar u.a.: Reusing Digital Collections From GLAM Institutions, in: Journal of Information Science 48 (2), 2022, S. 251–267. Online: <https://doi.org/10.1177/0165551520950246>.
22 Hearst, Marti: What is Text Mining?, 17.10.2003, <https://people.ischool.berkeley.edu/~hearst/text-mining.html>, Stand: 07.07.2022.
23 Kotu und Deshpande geben hierzu eine gute Erläuterung, vgl. Kotu, Vijay; Deshpande, Bala: Data Science: Concepts and Practice, Cambridge, MA 2019, S. 21. Online: <https://doi.org/10.1016/C2017-0-02113-4>.
24 Ebd., S. 8–9.
25 De Mauro, Andrea; Greco, Marco; Grimaldi, Michele: What is Big Data? A Consensual Definition and a Review of Key
Research Topics, in: AIP Conference Proceedings 1644 (1), 09.02.2015, S. 103. <https://doiorg/10.1063/1.4907823>.
26 Z.B. Distributed File Systems und NoSQL-Datenbanken sowie Anwendungen für Parallel Batch Processing, Data Stream Integration und Data Stream Processing.
27 International Federation of Library Associations and Institutions (IFLA): IFLA Statement on Digital Literacy, 18 August 2017, International Federation of Library Associations and Institutions (IFLA), 18.08.2017, S. 2. Online: <https://repository.ifla.org/handle/123456789/1283>.
28 Z.B. basale Programmierkenntnisse, Versionskontrolle, Virtualisierung, Umgang mit Cloud-Diensten.
29 Ridley, Michael; Pawlick-Potts, Danica: Algorithmic Literacy and the Role for Libraries, in: Information Technology and Libraries 40 (2), 2021, S. 3. <https://doi.org/10.6017/ital.v40i2.12963>.
30 Heidrich, Jens; Bauer, Pascal; Krupka, Daniel: Future Skills: Ansätze zur Vermittlung von Data Literacy in der Hochschulbildung, Arbeitspapier 37, Hochschulforum Digitalisierung, Berlin 2018. Online: <https://doi.org/10.5281/zenodo.1413119>.
31 Ridley; Pawlick-Potts: Algorithmic Literacy, 2021, S. 4.
32 Einen Überblick über internationale Umfragen zu Digital Humanities bzw. DS Services in Bibliotheken bietet Wilms, Lotte: Digital Humanities in European Research Libraries. Beyond Offering Digital Collections, in: LIBER Quarterly 31 (1), 2021, S. 1–23. Online: <https://doi.org/10.18352/lq.10351>.
33 Beispiele sind die LIBER Working Groups Digital Scholarship and Digital Cultural Heritage Collections, <https://
libereurope.eu/working-group/digital-scholarship-and-digital-cultural-heritage-collections-working-group/> und Data Science in Libraries, <https://libereurope.eu/working-group/liber-data-science-in-libraries-working-group/
documents-resources/>, das RLUK Digital Scholarship Network, <https://www.rluk.ac.uk/rluk-dsn/> sowie die
ALA/ACRL Digital Scholarship Section, <https://www.ala.org/acrl/aboutacrl/directoryofleadership/sections/dss/acr-dssec>.
34 Einige Beispiele sind die National Library of Scotland, Österreichische Nationalbibliothek, Staatsbibliothek zu Berlin, McGill University Library, Vanderbilt Libraries oder die University of Oslo Library.
35 Harris, Grant; Potter, Abigail; Zwaard, Kate u.a.: Digital Scholarship at the Library of Congress: User Demand, Current Practices, and Options for Expanded Services, Library of Congress, 17.03.2020. Online: <https://labs.loc.gov/static/labs/work/reports/DHWorkingGroupPaper-v1.0.pdf>. Der Report bzw. dessen Empfehlungen spiegeln den Stand Ende 2018 wider, als dieser an das Management der LoC übermittelt wurde. Zum Zeitpunkt der Veröffentlichung im März 2020 waren einige der Empfehlungen bereits umgesetzt.
36 Ebd., S. 2, 5.
37 Die Gewährspersonen stammten aus der Britischen, Niederländischen, und Dänischen Nationalbibliothek.
38 Harris u.a.: Digital Scholarship at the Library of Congress, 2020, S. 21–22.
39 Ebd., S. 2, 11–15.
40 Auf der Website LC for Robots, <https://labs.loc.gov/lc-for-robots/>, sind diese Angebote, mit Dokumentationen und Hilfestellungen, zusammengefasst. Einen Überblick über die digital vorliegenden Sammlungen und Zugang zu einzelnen Ressourcen bietet die Digital-Collections-Seite der LoC <https://www.loc.gov/collections/selected-datasets/>.
41 Harris u.a.: Digital Scholarship at the Library of Congress, 2020, S. 2, 16–21.
42 Ebd., S. 2, 22.
43 Ebd., S. 23.
44 Lippincott: Mapping, 2020.
45 Ebd., S. 3.
46 Ebd., S. 4–13.
47 Ebd., S. 5–7.
48 Ebd., S. 3–4.
49 Ebd., S. 7–14.
50 Ebd., S. 14–16.
51 Ebd., S. 14–17.
52 Ebd., S. 17–23.
53 Ebd., S. 18.
54 Ebd., S. 4.
55 Ames, Sarah; Lewis, Stuart: Disrupting the Library: Digital Scholarship and Big Data at the National Library of Scotland, in: Big Data & Society 7 (2), 2020. <https://doi.org/10.1177/2053951720970576>.
56 Ebd., S. 3.
57 Ebd., S. 5.
58 TDM-Plattformen sind eine neue Produktkategorie. Der Anbieter stellt vorverarbeitete Textdatenkonvolute bereit, oft in einer eigenen Analyseumgebung und mit bereits vorgefertigten Analyseskripten. Beispiele sind Nexis Data Lab, Gale Digital Scholarship Lab, ProQuest TDM Studio.
59 Ridley; Pawlick-Potts: Algorithmic Literacy, 2021, S. 9. Ein Beispiel für die Vermittlung von Computational und Data Science Literacy bietet Oliver (2019): Oliver, Jeffrey C.; Kollen, Christine; Hickson, Benjamin u.a.: Data Science Support at the Academic Library, in: Journal of Library Administration 59 (3), 2019, S. 244–245. Online: <https://doi.org/10.1080/01930826.2019.1583015>. Für Praxisbeispiele zur Förderung von Artificial Intelligence Literacy in Bibliotheken siehe “Part I: User Services” im Sammelband hrsg. von Hervieux und Wheatley (2022): Hervieux, Sandy; Wheatley, Amanda (Hg.): The Rise of AI: Implications and Applications of Artificial Intelligence in Academic Libraries, Chicago, Ill. 2022 (ACRL Publications in Librarianship 78). Die breite Mitwirkung von Bibliotheken an Data-Literacy-Programmen an deutschen Hochschulen wird in diesem Sammelband klar: Ebeling, Johanna; Koch, Henning; Roth-Grigori, Alexander (Hg.): Kompetenzerwerb im kritischen Umgang mit Daten: Data Literacy Education an deutschen Hochschulen, Essen 2021. Online: <https://www.stifterverband.org/medien/kompetenzerwerb-im-kritischen-umgang-mit-daten>, Stand: 13.06.2022.
60 Prudlo, Marion: Digital Scholarship an der UB Bern, Universitätsbibliothek Bern, 10.2019.
61 Woitas, Kathi: Digital Scholarship Services an der Universitätsbibliothek Bern, Universitätsbibliothek Bern, 15.06.2020.
62 Der Bericht von Sarah Lippincott (2020) erschien erst im Juli 2020 und konnte daher nicht einfliessen.
63 Woitas, Kathi: Digital Scholarship Services an der Universitätsbibliothek Bern: Umsetzung, Universitätsbibliothek Bern, 07.10.2020.
64 E-rara, Plattform für digitalisierte Drucke aus Schweizer Institutionen <https://www.e-rara.ch/>.
65 E-manuscripta, Plattform für digitalisierte handschriftliche Quellen aus Schweizer Bibliotheken und Archiven <https://www.e-manuscripta.ch/>.
66 E-periodica, Schweizer Zeitschriften online <https://www.e-periodica.ch/>.
67 DS Python Toolbox, Web-Tools <https://github.com/ub-unibe-ch/ds-pytools/tree/main/web-tools>.
68 UB Bern, Datenquellen für das Text- und Datamining <https://www.ub.unibe.ch/service/digital_scholarship/tdm/index_ger.html>.
69 Gebru, Timnit; Morgenstern, Jamie; Vecchione, Briana u.a.: Datasheets for Datasets, in: arXiv:1803.09010 [cs], 19.03.2020. Online: <http://arxiv.org/abs/1803.09010>, Stand: 21.02.2021.
70 UB Bern, Application Programming Interfaces (APIs) <https://www.ub.unibe.ch/service/digital_scholarship/apis/index_ger.html#pane1208956>.
71 UB Bern, Digital Scholarship Services <https://www.ub.unibe.ch/service/digital_scholarship/index_ger.html>.
72 Z.B. Einstieg in das NLP, die Texterkennung aus PDF-Dateien und in Tabellen, Nutzung von Daten-APIs und Verarbeitung von Metadaten, vgl. DS Python Toolbox <https://github.com/ub-unibe-ch/ds-pytools>.
73 IGWBS: Interessengruppe Wissenschaftliche BibliothekarInnen Schweiz, Sektion der Bibliosuisse.
74 UZH/ZBZ: Universität Zürich, Zentralbibliothek Zürich.
75 Hinweise auf die Jupyter Notebooks zur API-Nutzung von nationalen Plattformen wurden etwa auf die Tools-Page der Digital Humanities der Universität Bern aufgenommen.
76 TDM-Plattformen werden als wertvolles neues Angebot in mehrere Disziplinen wahrgenommen. So müssen Nutzungs-
anfragen für eine TDM-Plattform mit Single-User-Account gestaffelt bearbeitet werden.
