
Konferenzbeiträge strategisch publizieren
Automatisierte Workflows zur individuellen Veröffentlichung von Konferenzbeiträgen am Beispiel des Verbands Digital Humanities im deutschsprachigen Raum e.V.
Patrick Helling, Data Center for the Humanities (DCH), Universität zu Köln
Anke Debbeler, Data Center for the Humanities (DCH), Universität zu Köln
Rebekka Borges, Rheinische Friedrich-Wilhelms-Universität Bonn
Zusammenfassung
Wissenschaftliche Konferenzen stellen ein wichtiges Forum für den fachlichen Austausch zwischen Forscher*innen dar. Sie dienen häufig als Schaufenster einzelner Fachbereiche. Die digitale Publikation von präsentierten Konferenzbeiträgen dokumentiert dabei zusätzlich aktuelle Entwicklungen eines Forschungsfeldes und erhöht die Sichtbarkeit der wissenschaftlichen Arbeit. Die tatsächliche Publikationspraxis einzelner Konferenzen unterscheidet sich mitunter deutlich. In diesem Beitrag stellen wir automatisierte Prozesse zur Publikation von Konferenzbeiträgen am Beispiel der Jahreskonferenzen des Verbands „Digital Humanities im deutschsprachigen Raum” e.V. vor. Im Fokus steht dabei die Weiterentwicklung der bisherigen Publikationsprozesse des Verbands vom Sammelband zur individuellen Einzelpublikation der Konferenzbeiträge.
Abstract
Academic conferences are an important platform for scientific exchange between researchers. They often serve as a showcase for individual disciplines. The digital publication of presented conference papers also documents current developments in a research field and increases the visibility of scientific work. The actual publication practice of individual conferences sometimes differs significantly. In this article, we present automated processes for the publication of conference papers based on the example of the annual conferences of the association “Digital Humanities im deutschsprachigen Raum” e.V. The focus lies on the further development of the association’s publication processes from collective volumes to the individual publication of conference papers.
Zitierfähiger Link (DOI): https://doi.org/10.5282/o-bib/5835
Schlagwörter: Kongressbericht, Elektronische Publikation, Bibliografie, Workflow, Arbeitsablauf, Digital Humanities
Autorenidentifikation:
Patrick Helling: ORCID: 0000-0003-4043-165X
Anke Debbeler: ORCID: 0000-0001-5864-8465
Rebekka Borges: ORCID: 0000-0002-4651-5638
Dieses Werk steht unter der Lizenz Creative Commons Namensnennung 4.0 International.
1. Einleitung
Die Einreichung und Präsentation von Beiträgen auf wissenschaftlichen Konferenzen und Fachtagungen stellen einen wichtigen Bestandteil wissenschaftlicher Arbeit dar. Sie ermöglichen einerseits die Kommunikation von Ergebnissen aus Forschungsprozessen, andererseits dienen sie als Basis für einen fachwissenschaftlichen Austausch mit Kolleg*innen. Dementsprechend fungieren sie als ein wichtiges Instrument zur Beförderung wissenschaftlichen Fortschritts. Die Publikation dieser Beiträge durch Konferenzveranstaltende bzw. Fachverbände stellt zusätzlich ein Organ zur Dissemination von Ergebnissen und Themen einer wissenschaftlichen Veranstaltung dar.
Die Praxis zur Veröffentlichung von Konferenzbeiträgen unterscheidet sich dabei häufig zwischen verschiedenen Konferenzen und Fachtagungen: Neben klassischen Printpublikationen werden Konferenzbeiträge mittlerweile auch zunehmend in digitaler Form publiziert. Digitale Konferenzbände i.S.v. Proceedings oder sogenannter Books of Abstracts bündeln durch die gesammelte Publikation von überarbeiteten Konferenzbeiträgen und Abstracts den Stand aktueller Forschungen. Aber auch andere Publikationsformen für Konferenzbeiträge wie bspw. Sondersammelbände als Teil (fachspezifischer) Journals sowie die Veröffentlichung von Konferenzbeiträgen als Einzelpublikationen, bspw. im PDF-Format oder als HTML-Website, werden zur Dokumentation und Präsentation einer Veranstaltung bzw. eines Forschungsfeldes verwendet. Jede dieser Publikationsformen konstituiert in ihrem Sinne einen Fachbereich sowohl nach innen als auch nach außen und dokumentiert die Entwicklungen einer Konferenz bzw. eines Forschungsfeldes.1
Die Beiträge der Jahreskonferenzen des Verbands „Digital Humanities im deutschsprachigen Raum” e.V. (DHd) werden seit der zweiten Jahreskonferenz gesammelt in Form eines Book of Abstracts im PDF-Format publiziert.2 Wenngleich diese Books of Abstracts ein wichtiges Schaufenster des Fachbereichs der Digital Humanities (DH) im deutschsprachigen Raum darstellen, ermöglichen sie weder eine individuelle Zitier- und Referenzierbarkeit einzelner fachlicher Beiträge im Rahmen weiterführender Arbeiten, noch können die enthaltenen Einzelbeiträge in digitalen Katalogen und Findmitteln individuell indexiert werden.3 Um die Auffindbarkeit, Zugänglichkeit und Nachnutzbarkeit der DHd-Konferenzbeiträge im Sinne der FAIR-Prinzipien zu verbessern, ist eine zusätzliche Veröffentlichung von Tagungs- und Konferenzbeiträgen als einzeln zitier- und referenzierbare Publikationen notwendig.4
Vor diesem Hintergrund hat der DHd-Verband auf seiner Jahreskonferenz 2020 in Paderborn die Stelle eines DHd Data Stewards eingerichtet.5 Eine zentrale Aufgabe des DHd Data Stewards ist die Optimierung der Publikationsprozesse für wissenschaftliche Beiträge von DHd-Jahreskonferenzen. Im vorliegenden Beitrag soll die Arbeit des DHd Data Stewards vorgestellt werden.6 Im Fokus steht dabei die Vorstellung von Workflows zur nachhaltigen sowie individuell referenzier- und zitierbaren Veröffentlichung von Konferenzbeiträgen als Einzelpublikationen am Beispiel der Jahreskonferenzen des DHd-Verbands.
2. Ausgangssituation im DHd-Verband
Der Verband „Digital Humanities im deutschsprachigen Raum” e.V. vertritt seit seiner Gründung auf der „DHd Unconference” 2012 in Hamburg die digitalen Geisteswissenschaften / Digital Humanities in Deutschland, Österreich und der Schweiz.7 Als eingetragener Verein verfügt der DHd-Verband über eine eigene Satzung und einen Vorstand, welcher aus insgesamt sieben Hauptmitgliedern unterschiedlicher geisteswissenschaftlicher Fachrichtungen sowie aktuell drei kooptierten Mitgliedern für spezifische Aufgabenbereiche besteht (Stand: Mai 2022).8 Der DHd-Verband, der mittlerweile rund 400 Mitglieder führt, agiert als transnationale Interessensvertretung im Kontext unterschiedlicher internationaler Digital-Humanities-Verbände, insbesondere der European Association for Digital Humanities (EADH) und der Alliance of Digital Humanities Organizations (ADHO).9
Seit 2014 findet jedes Jahr (mit einer COVID-19 bedingten Ausnahme 2021) eine zentrale DHd-Jahreskonferenz statt, die durch wechselnde DH-Institutionen, -Lehrstühle und -Institute in Deutschland, Österreich und der Schweiz organisiert wird. Mittlerweile nehmen jährlich zwischen 500 und 600 Wissenschaftler*innen an den Tagungen teil. Im Durchschnitt werden ca. 130 Beiträge in den Formaten Vortrag (Umfang: 1500-2000 Wörter), Panel (Umfang: 1200-1500 Wörter), Workshop (Umfang: 1200-1500 Wörter), Poster (Umfang: 500-750 Wörter) und Doctoral Consortium (Umfang: 500-750 Wörter) (seit 2020) präsentiert. Mit Ausnahme der ersten DHd-Jahreskonferenz 2014 in Passau wurde zu jeder Jahreskonferenz ein Book of Abstracts mit allen präsentierten und durch ein Peer Review Verfahren begutachteten Beiträgen digital publiziert.10 Die Erstellung und Veröffentlichung des Book of Abstracts ist dabei eine zentrale Aufgabe des jeweiligen Organisationskomitees der Jahreskonferenz.
2.1. Der Entstehungs- und Publikationsprozess der DHd Books of Abstracts
Die technischen und redaktionellen Prozesse zur Einreichung von Konferenzbeiträgen sowie zur Erstellung der Books of Abstracts zu den einzelnen DHd-Jahreskonferenzen durch die jeweiligen Organisationskomitees sind historisch gewachsen und haben sich mittlerweile verfestigt: Um einen Konferenzbeitrag zu einer DHd-Jahreskonferenz einzureichen, müssen Autor*innen in einer individuellen Instanz des digitalen Verwaltungssystems ConfTool, welches für jede Jahreskonferenz aufgesetzt wird, zunächst (1) einen Konferenzbeitrag anlegen.11 In diesem Prozess müssen grundsätzliche Metadaten zum geplanten Konferenzbeitrag, bspw. Titel, Zusammenfassung, Autor*innen-Namen, Affiliation, sofern vorhanden die entsprechenden ORCID (seit der Jahreskonferenz 2022) sowie von den Autor*innen selbst zu vergebene Schlagwörter, eingetragen werden.12 Zusätzlich müssen Autor*innen mit Hilfe der Taxonomy of Digital Research Activities in the Humanities (TaDiRAH), deren einzelne Elemente durch Checkboxen auswählbar sind, den Konferenzbeitrag kategorisieren.13, 14
Die im ConfTool eingetragenen Metadaten werden über eine Schnittstelle automatisch in das Transformationstool DH-Convalidator eingespeist. In diesem kann schließlich durch die Autor*innen (2) ein individuelles Word-Template zu dem zuvor im ConfTool eingerichteten Konferenzbeitrag erzeugt werden, welches die entsprechenden Metadaten zum Konferenzbeitrag beinhaltet.15
Wenn das Template durch die Autor*innen mit dem eigentlichen Konferenzbeitrag (einschließlich der Bibliografie) befüllt wurde, müssen sie dieses (3) wieder in den DH-Convalidator hochladen. Dieser prozessiert die Daten des Templates und erzeugt schließlich eine .dhc-Datei. Sie enthält das befüllte Template, eine HTML- und eine TEI-codierte XML-Version des Konferenzbeitrags sowie, falls vorhanden, verwendete Abbildungen.
Zum Abschluss der Einreichung müssen die Autor*innen diese .dhc-Datei wieder (4) im ConfTool zum angelegten Konferenzbeitrag hochladen.
Die TEI-XML-Dateien der nach dem Reviewprozess angenommenen Konferenzbeiträge werden schließlich vom Organisationskomitee der jeweiligen DHd-Jahreskonferenz für die (weitestgehend) automatisierte Generierung des Book of Abstracts genutzt.16 Sie enthalten die eingetragenen Metadaten der Beiträge aus dem ConfTool, Verweise auf mitgelieferte Abbildungen sowie den Beitrag selbst inklusive Bibliografie und Fußnoten.
Diese formalisierte Datenbasis stellt grundsätzlich einen soliden Ausgangspunkt für die automatisierte Generierung eines Book of Abstracts dar. Aufgrund individueller Nutzung unterschiedlicher Textverarbeitungsprogramme der Autor*innen werden jedoch häufig zusätzliche Darstellungs- und Layoutinformationen in das Template und somit in den TEI-XML-Output übernommen. Als Folge weisen die TEI-XML-Strukturen Ungenauigkeiten auf und es bedarf i.d.R. einer grundsätzlichen Datenbereinigung vor der Erstellung des Book of Abstracts.
Für die automatisierte Erstellung des Book of Abstracts werden schließlich die gesammelten und bereinigten TEI-XML-Dateien sowie alle Abbildungen mit Hilfe von XSL-Transformationsskripten und einem Shell-Skript zu einem entsprechenden Sammelband im PDF-Format zusammengefasst. Die Transformationsskripte basieren auf Skripten zur Erstellung des Book of Abstracts zur internationalen Digital Humanities Konferenz 2013.17
Alle redaktionellen Bearbeitungen und die Darstellung von Sonderschriftzeichen sowie die Hinzufügung eines Deckblatts, die Erstellung von Inhalts- und Autor*innenverzeichnis sind innerhalb der Transformationsskripte definiert.
Mit Hilfe dieses Prozesses wurden durch die jeweiligen Organisationskomitees der verschiedenen DHd-Jahreskonferenzen bereits sechs Books of Abstracts über den generischen Online-Speicherdienst Zenodo veröffentlicht.18 Jedes Book of Abstracts verfügt über einen Digital Object Identifier (DOI) und wurde einer durch den DHd-Verband kuratierten Zenodo-Community für Konferenzpublikationen zugeordnet.19 Bei der DHd-Jahreskonferenz 2015 wurde das Book of Abstracts aus eingereichten PDF-Dateien generiert und auf der institutionell betriebenen Website zur Jahreskonferenz veröffentlicht.20 Zur ersten Jahreskonferenz 2014 wurde kein Book of Abstracts publiziert.
Die Erstellung und gesammelte Publikation aller Konferenzbeiträge in Books of Abstracts stellt den Status quo in der Publikationsstrategie des DHd-Verbands dar. Aufbauend auf diesem Publikationsprozess wurden im Rahmen der DHd Data Steward Tätigkeit technische und organisatorische Workflows zur gesonderten Veröffentlichung der Konferenzbeiträge als zusätzliche Einzelpublikationen entwickelt. Zum Zweck der wissenschaftlichen Nachnutzung wurde darüber hinaus ein quasi-Standard zur zentralen Veröffentlichung der DHd-Konferenzbeiträge als TEI-XML-Daten eingeführt und umgesetzt.
3. Individuelle Publikation der einzelnen Beiträge der DHd-Jahreskonferenzen
3.1. Community-getriebene Vorüberlegungen
Mögliche Potentiale, die aus weiterführenden Publikationsbestrebungen entstehen könnten, sowie zusätzliche Überlegungen zur verbesserten, wissenschaftlichen Auswertung von Konferenzbeiträgen im Kontext des DHd-Verbands wurden durch die deutschsprachige Digital Humanities Community adressiert. In seinem Tagungsbericht zur DHd-Jahreskonferenz 2018 reflektiert Cremer bereits den aufwändigen Prozess der Beitragseinreichungen der DHd-Jahreskonferenzen und verweist auf das Problem, dass die Konferenzbeiträge (noch zu) selten als verarbeitbare Daten, bspw. in ihrer TEI-XML-Version, veröffentlicht werden bzw. auffindbar sind.21 Gleichzeitig illustrieren Hannesschläger und Andorfer mit ihrer Analyse zu Geschlechterverteilungen auf der TEI Konferenz 2016, die sie an den entsprechenden TEI-XML-Dateien der Beiträge zur Konferenz durchgeführt haben, welche Potentiale Analysen von Konferenzbeiträgen haben können.22 Mit der DH(d) Konferenzbeiträge Bibliographie konnte schließlich eine bis dahin noch nicht vorhandene Sammlung bibliografischer Einträge zu den DHd-Konferenzbeiträgen der Jahreskonferenzen 2016, 2018, 2019 und 2020 aufgebaut werden.23 Zusätzlich wurde mit der dhd-boas-app eine analysierbare Datenbank zu den DHd-Konferenzbeiträgen der Jahreskonferenzen 2016, 2018, 2019 und 2020 entwickelt, die unter anderem Topic Modelling Analysen ermöglicht und das grundsätzliche Analysepotential der DHd-Konferenzbeiträge noch einmal unterstreicht.24 Eine durch die Community getragene Diskussion über den Umgang mit DHd-Konferenzbeiträgen sowohl aus einer Publikations- als auch aus einer Datenanalyse-Perspektive wurde schließlich seit der DHd-Jahreskonferenz 2019 kontinuierlich in verschiedenen Konferenzbeitrags- und Veranstaltungsformaten geführt.25
Vor dem Hintergrund dieser Vorüberlegungen ist das zentrale Ziel einer zusätzlichen Einzelpublikation der DHd-Konferenzbeiträge durch den DHd Data Steward die Erhöhung der Sichtbarkeit und Zugänglichkeit eben dieser selbst. Sie bietet die Möglichkeit, die DHd-Konferenzbeiträge mit individuellen Metadaten zu beschreiben und, im Gegensatz zur Veröffentlichung innerhalb eines Book of Abstracts im PDF-Format, besser in Online-Katalogen und Findmitteln indexiert und auffindbar zu machen. Eine eindeutige und direkte Zitation einzelner Konferenzbeiträge über individuelle Persistent Identifier wird ermöglicht. Darüber hinaus konnten zusätzlich Strukturen geschaffen werden, die nicht nur eine Nachnutzung der Konferenzbeiträge als Publikationen verbessern, sondern auch als Daten für weitere Analysen ermöglichen.
3.2. Vorüberlegungen des DHd Data Stewards
Aufgrund der Tatsache, dass die meisten Books of Abstracts der DHd-Jahreskonferenzen (2016-2020) bereits auf dem Online Speicherdienst Zenodo publiziert und der DHd-Zenodo Community zugeordnet wurden, wurde auch für die Publikation der einzelnen DHd-Konferenzbeiträge Zenodo als Publikationsplattform gewählt.
Der Online-Speicherdienst wird langfristig von der European Organization for Nuclear Research (CERN) in der Schweiz betrieben, ist generisch auf die Publikation unterschiedlichster digitaler Objekte ausgelegt und verpflichtet sich gegenüber den FAIR-Prinzipien.26 Er erfüllt wesentliche Grundbedingungen für die auffindbare, zugängliche, interoperable und nachnutzbare Ablage von Publikationen und verfügt über eine dokumentierte REST API-Schnittstelle, die für den automatisierten Upload von Publikationen genutzt werden kann.27
Veröffentlichungen auf Zenodo können mit einem reichhaltigen Metadatenschema, welches sich am DataCite-Metadatenschema orientiert, beschrieben und ausgezeichnet werden.28 Auf diese Weise können beispielsweise auch Konferenzen, auf denen die zu publizierenden Beiträge präsentiert wurden, beschrieben werden. Alle Publikationen auf Zenodo erhalten einen versionierten Digital Object Identifier (DOI), wodurch auch Versionen von Publikationen einzeln oder gesammelt referenziert werden können. Zusätzlich besteht die Möglichkeit, Lizenzen zu vergeben und Zugriffsrechte zu definieren.
3.3. Sammlung, Sichtung und Vorverarbeitung der DHd-Konferenzbeiträge
Zur Einzelpublikation der DHd-Konferenzbeiträge der vergangenen DHd-Jahreskonferenzen mussten zunächst alle entsprechenden TEI-XML-Dateien gesammelt werden. Für die Jahrgänge 2016, 2018, 2019 und 2020 waren zum Zeitpunkt der Vorbereitungen alle TEI-XML-Dateien sowie alle Abbildungen zu den Konferenzbeiträgen über verschiedene GitHub-Repositorien öffentlich verfügbar.29 Die TEI-XML-Dateien zur DHd-Jahreskonferenz 2017 konnten über die lokalen Organisator*innen der Konferenz zur Verfügung gestellt werden.
Für die DHd-Jahreskonferenzen 2014 und 2015 existieren keine TEI-XML-Dateien. Für die Jahreskonferenz 2014 konnten die meisten Konferenzbeiträge durch die lokalen Organisator*innen sowie durch einen öffentlichen Aufruf auch durch die Community selbst in PDF- und Word-Formaten zur Verfügung gestellt werden. Für die Jahreskonferenz 2015 liegt ein Book of Abstracts im PDF-Format vor, welches manuell in die einzelnen Konferenzbeiträge getrennt wurde (siehe Tab. 1). Auf diese Weise konnten insgesamt 917 Konferenzbeiträge der DHd-Jahreskonferenzen 2014-2020 gesammelt werden (siehe Tab. 2).
Tab. 1: Übersicht der Verfügbarkeit der Daten zu den Konferenzbeiträgen der DHd-Jahreskonferenzen.
|
Jahr |
Verfügbarkeit der Daten |
|
2014 |
Word-/PDF-Dateien via lokale Organisator*innen der Jahreskonferenz/DHd-Community |
|
2015 |
Konferenzbeiträge als Book of Abstracts im PDF-Format |
|
2016 |
TEI-XML-Dateien via GitHub |
|
2017 |
TEI-XML-Dateien via lokale Organisator*innen der Konferenz |
|
2018 |
TEI-XML-Dateien via GitHub |
|
2019 |
TEI-XML-Dateien via GitHub |
|
2020 |
TEI-XML-Dateien via GitHub |
Zur Vorverarbeitung der TEI-XML-Dateien der Jahreskonferenzen 2016-2020 wurden die bereits existierenden Transkriptionsskripte zur Erstellung von Books of Abstracts aus TEI-XML-Dateien (s.o.) angepasst, sodass aus den Ausgangsdaten einzelne PDF-Dateien zu jedem Konferenzbeitrag generiert werden konnten.30 Zwecks Zuordnung entspricht der Dateiname der PDF-Dateien jeweils dem Namen der jeweiligen TEI-XML-Datei.31 Bei den einzelnen PDF-Dateien zu den DHd-Jahreskonferenzen 2014 und 2015 wurde jeweils ein individuelles Schema zur Dateibenennung gewählt (siehe auch Tab. 3).
Tab. 2: Anzahl der gesammelten Konferenzbeiträge der DHd-Jahreskonferenzen 2014-2020.
|
Jahr |
Anzahl der zu publizierenden Konferenzbeiträge |
|
2014 |
100 Konferenzbeiträge im PDF-Format |
|
2015 |
131 Konferenzbeiträge im PDF-Format |
|
2016 |
160 Konferenzbeitrage sowohl im TEI-XML- als auch im PDF-Format |
|
2017 |
92 Konferenzbeitrage sowohl im TEI-XML- als auch im PDF-Format |
|
2018 |
160 Konferenzbeitrage sowohl im TEI-XML- als auch im PDF-Format |
|
2019 |
137 Konferenzbeitrage sowohl im TEI-XML- als auch im PDF-Format |
|
2020 |
137 Konferenzbeitrage sowohl im TEI-XML- als auch im PDF-Format |
Darüber hinaus wurden mit weiteren XSL-Transformationsskripten aus den TEI-XML-Dateien für die Jahrgänge 2016-2020 jeweils eine Konferenz-Metadatendatei im XML-Format generiert, die dem DataCite-Metadatenschema und somit den Anforderungen von Zenodo entsprechen.32 Um dies zu realisieren, wurden die TEI-XML-Dateien der einzelnen Jahreskonferenzen zunächst zu einer Gesamtdatei zusammengeführt, wobei das xml:id-Attribut bei einigen DHd-Jahreskonferenzen aus den TEI-Headern entfernt werden musste.33 Aus den jeweiligen Gesamtdateien konnten dann die benötigten individuellen Metadaten zu den Konferenzbeiträgen extrahiert und in einer Konferenz-Metadatendatei zusammengefasst werden. Schließlich wurde aus den Konferenz-Metadatendateien für jeden Konferenzbeitrag eine einzelne JSON-Datei mit den entsprechenden Metadaten erstellt. Für die DHd-Jahreskonferenzen 2014 und 2015 wurden entsprechende Konferenz-Metadatendateien manuell erstellt.
Die verwendeten Metadaten umfassen inhaltliche und bibliografische Daten, Angaben zur jeweiligen Jahreskonferenz sowie eine generische <description> (bspw. „A single abstract from the DHd-2018 Book of Abstracts.“). Zusätzlich wurde eine <reference> zum jeweiligen Book of Abstracts, in dem der Konferenzbeitrag bereits veröffentlicht wurde, hinzugefügt. Auch Angaben zu Editor*innen sowie redaktionelle Hinweise zur Verarbeitung als <note> wurden angegeben. Bei der Verschlagwortung der Konferenzbeiträge, für die die durch die Autor*innen selbst vergebenen Schlagworte sowie die TaDiRAH-Auswahl verwendet wurden, wurde zusätzlich das Akronym der jeweiligen DHd-Jahreskonferenz (bspw. „DHd2018”) hinzugefügt. Auf diese Weise können nach Abschluss des Publikationsprozesses über das Interface von Zenodo alle einzelnen Publikationen der jeweiligen DHd-Jahreskonferenz ausgewählt und angezeigt werden. Um die Publikationen im Upload-Prozess direkt der durch den DHd-Verband kuratierten Zenodo Community zuordnen zu können, wurde auch der entsprechende Community-Identifier „dhd” hinzugefügt. Alle Konferenzbeiträge verfügen über eine CC-BY Lizenz und wurden als open access getagged.34
3.4. Der Publikationsprozess
Für die technische Umsetzung des Publikationsworkflows wurde eine Python-Anwendung geschrieben, die zur Nachnutzung auch auf GitHub unter einer MIT-Lizenz veröffentlicht wurde.35 Die Anwendung umfasst zwei Hauptfunktionen: Im ersten Schritt werden (1) einzelne Ordner (Bundles) pro Konferenzbeitrag erstellt, die eine PDF-Version und (sofern vorhanden) eine TEI-XML-Version eines einzelnen DHd-Konferenzbeitrags sowie eine entsprechende Metadatendatei im JSON-Format, die aus der jeweiligen Konferenz-Metadatendatei erstellt wurde, enthalten (siehe Abb. 1). Anschließend wird über die Anwendung (2) die Anbindung an Zenodo über die Zenodo REST API realisiert und der automatisierte Upload sowie die Publikation der Beiträge durchgeführt.

Abb. 1: Zugrundeliegende Ordnerstruktur eines Bundles für den Publikations-Workflow
3.4.1. Erstellung der Bundles pro Konferenzbeitrag
Das Zusammenführen der zu den einzelnen Konferenzbeiträgen zugehörigen Dateien in Bundles wurde zunächst über Konventionen der Dateibenennung realisiert. Die Dateinamen der PDF-Dateien sowie der TEI-XML-Dateien der DHd-Jahreskonferenzen 2016-2020 entsprechen den xml:id-Attributen der Konferenzbeiträge. Bei den einzelnen PDF-Dateien der DHd-Jahreskonferenzen 2014 und 2015, zu denen keine Konventionen in der Dateibenennung existieren, wurde ein eigenes Schema zur Dateibenennung gewählt. Die Benennungen unterscheiden sich je DHd-Jahreskonferenz; innerhalb einer Jahreskonferenz sind sie allerdings einheitlich (siehe Tab. 3).
Tab. 3: Unterschiedliche Konventionen bei der Dateibenennung der Beträge zu den verschiedenen DHd-Jahreskonferenzen.
|
Jahr |
Schema Dateibenennung |
|
2014 |
[LAST_NAME_OF_CREATOR]_[FIRST_NAME_OF_CREATOR]_[TITLE]* |
|
Beispiel: ARZHANOV_Yuri_The_Glossarium.pdf* |
|
|
2015 |
[ID]_[SLOT]_[LAST_NAME_OF_CREATOR]_[TITLE]_[NUMBER]* |
|
Beispiel: 150225_Philologie_III_3_de_Kok-Weblicht-1151162.pdf* |
|
|
2016 |
[PUBLICATION_TYPE]_[NUMBER] |
|
Beispiel: Panels-006.xml |
|
|
2017 |
[PUBLICATION_TYPE]_[LAST_NAME_OF_CREATOR] |
|
Beispiel: Panel-FEIGE.xml |
|
|
2018 |
[LAST_NAME_CREATOR]_[FIRST_NAME_CREATOR]_[TITLE] |
|
Beispiel: BARZEN_Johanna_SustainLife_Erhalt_lebender_digitaler_Syst.xml |
|
|
2019 |
[ID]_[LAST_NAME_CREATOR]_[FIRST_NAME_CREATOR]_[TITLE] |
|
Beispiel: 119_SCHASSAN_Torsten_Erneuerung_der_Digitalen_Editionen_an_der_H.xml |
|
|
2020 |
[ID]_[LAST_NAME_CREATOR]_[FIRST_NAME_CREATOR]_[TITLE] |
|
Beispiel: 107_HADERSBECK_Maximilian_Nachlass_Ludwig_Wittgenstein_Software.xml |
|
*Das Schema zur Dateibenennung wurde im Vorverarbeitungsprozess manuell gewählt.
Für die Konferenzbeiträge der DHd-Jahreskonferenzen 2018-2020 konnten zunächst mit einem automatisierten Abgleich der Dateinamen entsprechend zusammengehörende PDF- und TEI-XML-Dateien identifiziert und in einem Bundle zusammengeführt werden. Die Informationen aus den Dateinamen wurden schließlich auch dazu verwendet, den passenden Metadaten-Eintrag in der jeweiligen Konferenz-Metadatendatei zu identifizieren und im JSON-Format dem entsprechenden Bundle zuzuordnen. Aufgrund von unzuverlässiger Ersetzung von Sonder- sowie Leerzeichen durch ‘_’ in den Dateinamen, konnte allerdings keine fehlerfreie Zuweisung aller Dateien zu einem Konferenzbeitrag erfolgen. Entsprechend wurde dazu übergegangen, eine Zuordnung von PDF- und TEI-XML-Dateien sowie passendem Metadaten-Eintrag im JSON-Format über eine chronologische bzw. alphabetische Reihenfolge der Dateien zu realisieren. Zu diesem Zweck wurde die Reihenfolge der Metadaten-Einträge in der jeweiligen Konferenz-Metadatendatei der Reihung von PDF- bzw. TEI-XML-Dateien angepasst. Der manuelle Kontrollaufwand beider Vorgehensweisen ist identisch, die Menge an zu korrigierenden Zuweisungen ist beim zweiten Vorgehen allerdings deutlich geringer.
Darüber hinaus existieren für die Jahreskonferenzen 2014 und 2015 keine vorgegebenen Konventionen für die Dateibenennung. Bei den DHd-Jahreskonferenzen 2016 und 2017 wurde ein Schema zur Dateibenennung der TEI-XML-Dateien verwendet, das keine Informationen über Autor*innen oder Beitragstitel enthält. Entsprechend hat sich auch für diese vier Jahrgänge die Bundle-Erstellung nach chronologischer bzw. alphabetischer Ordnung empfohlen.
Nach der Zuordnung der PDF-Dateien, der TEI-XML-Dateien (sofern vorhanden) sowie der Metadateneinträge zu individuellen Bundles pro Konferenzbeitrag wird schließlich automatisch überprüft, ob jedes erstellte Bundle die korrekte Anzahl an Dateien enthält. Für eine zusätzliche manuelle Überprüfung wird eine CSV-Datei für jede DHd-Jahreskonferenz mit einer Übersicht der generierten Bundles erstellt. Die CSV-Dateien enthalten für jedes Bundle eine Übersicht mit dem Titel der Publikation aus der JSON-Metadatendatei, den Dateinamen der PDF- und ggf. der TEI-XML-Dateien sowie die aus den TEI-XML-Dateien extrahierten Titel der Publikation (Workflow zur Bundle-Erstellung siehe Abb. 2).
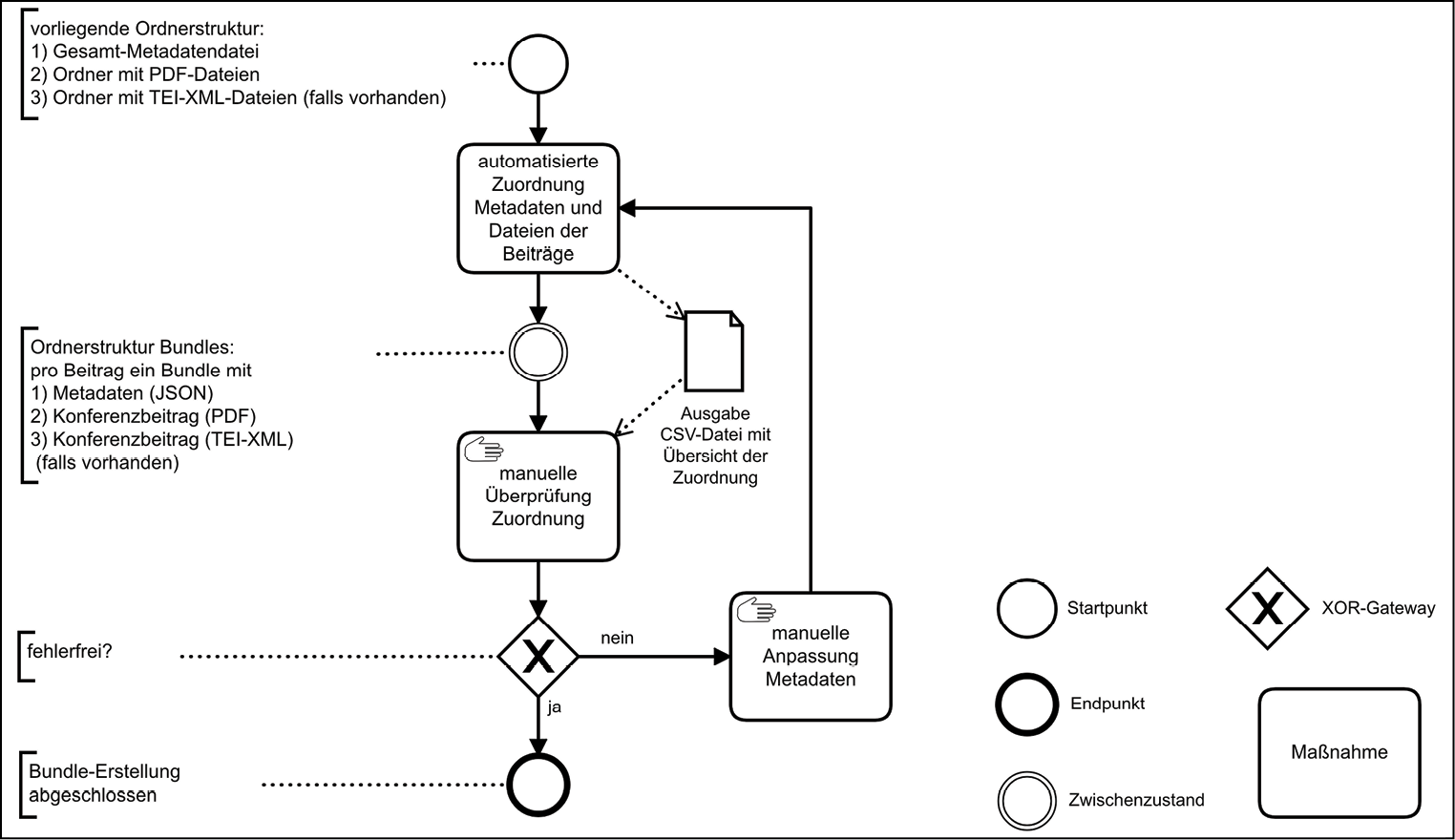
Abb. 2: Workflow zur Bundle-Erstellung.
3.4.2. Automatisierter Upload der Bundles auf Zenodo
Der Upload der einzelnen Bundles über die Zenodo REST API erfolgt mit einem Funktionsaccount des DHd-Verbands, über den auch die Zenodo-Community des Verbands kuratiert wird (Publikationsworkflow siehe Abb. 3). Beim Upload der Konferenzbeiträge auf Zenodo werden für jedes Bundle die Metadaten aus der JSON-Datei gelesen und zusammen mit den jeweiligen PDF- und ggf. TEI-XML-Dateien als Draft-Deposits gespeichert. Die dabei von Zenodo generierte Deposition-ID wird für alle Bundles einer Jahreskonferenz in einer Textdatei gespeichert.36 Schließlich werden die hochgeladenen Drafts über das User Interface von Zenodo ein letztes Mal manuell überprüft und bei Bedarf korrigiert: Individuelle Fehler wie bspw. falsch oder nicht übertragene einzelne Metadaten können manuell korrigiert werden. Fallen bei der manuellen Überprüfung systematische Fehler auf, können die Drafts auf Zenodo automatisiert gelöscht, die Fehler in der jeweiligen Metadatendatei oder in den Python-Skripten korrigiert und der Workflow erneut gestartet werden.
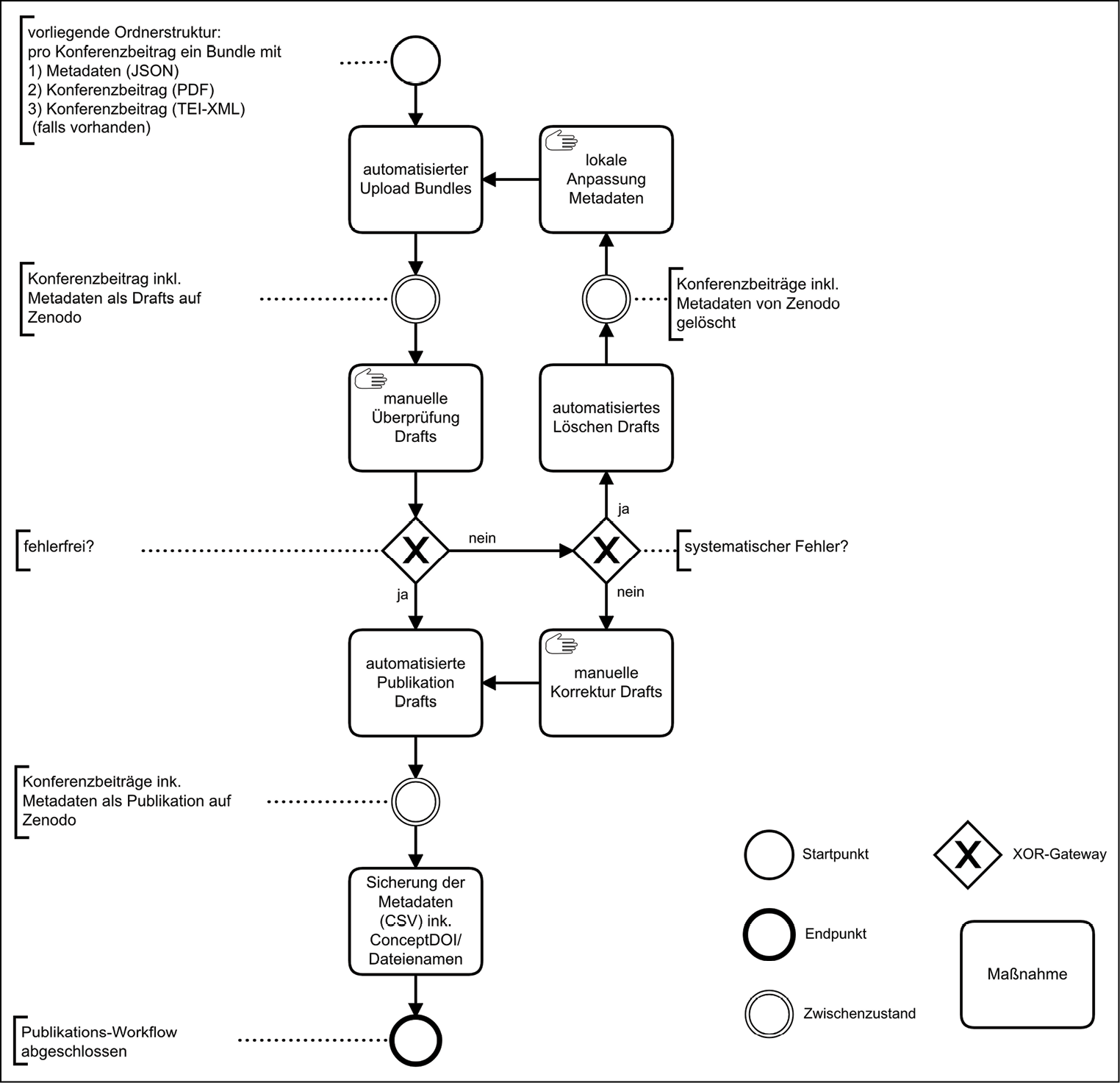
Abb. 3: Der Publikationsworkflow.
Nach einer letzten Überprüfung und ggf. Korrektur der Drafts werden die Uploads zur jeweiligen DHd-Jahreskonferenz schließlich automatisiert veröffentlicht. Zum Zweck der Dokumentation wird zuletzt eine Übersicht der publizierten Konferenzbeiträge, der final verwendeten Metadaten sowie der zugeordneten DOIs, über die Zenodo REST API in einer CSV-Datei extrahiert.
Zu jeder DHd-Jahreskonferenz, zu der die Konferenzbeiträge über die beschriebenen Workflows vorbereitet und publiziert wurden, wurde zusätzlich ein GitHub-Repositorium über den GitHub-Account des DHd-Verbands eingerichtet. Diese Repositorien enthalten alle PDF-Dateien der einzelnen Konferenzbeiträge, sofern vorhanden die zugehörigen TEI-XML-Dateien, die für den Upload verwendete Konferenz-Metadatendatei sowie die am Ende des Prozesses generierte CSV-Datei zu den Publikationen.37 Neben der Dokumentation der Vorverarbeitungs- und Publikationsprozesse ermöglichen diese GitHub-Repositorien auch explizit die Nachnutzung der Daten und Prozesse für weitere inhaltliche Analysen und Auswertungen der Konferenzbeiträge zu DHd-Jahreskonferenzen.
4. Erfahrungen im Rahmen der DHd-Jahreskonferenz 2022
Die beschriebenen Workflows und Prozesse basieren auf der Anforderung, die Konferenzbeiträge der bereits abgeschlossenen DHd-Jahreskonferenzen 2014-2020 zu verarbeiten und persistent zu publizieren. Im Jahr 2022 wurden diese Workflows und Prozesse schließlich das erste Mal im Vorfeld einer anstehenden DHd-Jahreskonferenz durchgeführt. Ziel dabei war es, die Konferenzbeiträge bereits vor der eigentlichen Jahreskonferenz persistent sowohl gesammelt in einem Book of Abstracts als auch als individuelle Einzelpublikationen zu veröffentlichen. Die bis hierhin entwickelten Workflows und Prozesse haben sich auch im Szenario einer bevorstehenden Jahreskonferenz grundsätzlich bewährt. Neben dem Book of Abstracts konnten insgesamt 154 Konferenzbeiträge zur DHd-Jahreskonferenz 2022 in der DHd-Community auf Zenodo publiziert werden.38 Zusätzlich wurde der Publikationsprozess genutzt, um das erste Mal in der Geschichte der DHd-Jahreskonferenzen auch die Posterpräsentation zu den Posterbeiträgen persistent auf Zenodo zu veröffentlichen.39 Insgesamt konnten auf diese Weise 61 Posterpräsentationen publiziert und mit den jeweiligen Konferenzbeiträgen verknüpft werden.
Dennoch haben sich, nicht zuletzt resultierend aus der Terminierung der Publikation vor Konferenzbeginn, einige lessons learned ergeben: Vor dem Hintergrund, dass die Erstellung eines gesammelten Book of Abstracts im Aufgabenbereich des jeweiligen lokalen Konferenz-Organisationskomitees liegt und die Datenbasis für das Book of Abstracts sowie für die Veröffentlichung der Konferenzbeiträge als Einzelpublikationen identisch ist, bedarf es eines frühzeitigen und regelmäßigen Austauschs zwischen dem DHd Data Steward und dem lokalen Organisationskomitee. Hierbei ist eine Zusammenarbeit insbesondere bei der Bereinigung der TEI-XML-Dateien sowie erweiterter/veränderter Metadaten, welche durch das lokale Konferenz-Organisationskomitee erfasst werden, von zentraler Bedeutung.
So wurde bspw. im Rahmen der DHd-Jahreskonferenz 2022 im Einreichungsprozess für Konferenzbeiträge zum ersten Mal die ORCID der Autor*innen abgefragt und in die Metadaten der TEI-XML-Dateien übernommen. Folglich war es auch erforderlich, die ORCID-Angaben bei der Erstellung der Metadaten für den Publikationsprozess der Konferenzbeiträge als Einzelpublikationen zu integrieren und bei der Veröffentlichung mit zu berücksichtigen. Darüber hinaus müssen grundsätzlich frühzeitig redaktionelle Abstimmungen und Anpassungen im Layout der Publikationen gemeinsam geklärt und umgesetzt werden.
5. Ausblick
Mit Hilfe der in diesem Beitrag beschriebenen Workflows und Prozesse konnten die Auffindbarkeit, Zitierbarkeit und individuelle Referenzierbarkeit der Konferenzbeiträge zu DHd-Jahreskonferenzen via Zenodo grundsätzlich verbessert werden. Zusätzlich konnten auf diese Weise die DHd-Konferenzbeiträge mittlerweile durch das Digital Bibliography & Library Project (DBLP) und den Index of Digital Humanities Conferences indexiert werden.40
Die entwickelten Workflows stellen dabei einen pragmatischen Ansatz dar, der explizit auf die Ausgangssituation und insbesondere die Datengrundlage ausgerichtet ist, die sich im Rahmen der DHd-Jahreskonferenzen ergeben. Nichtsdestotrotz konnten der Vorverarbeitungs- und Publikationsprozess in Teilen bereits im Rahmen weiterer Konferenzen nachgenutzt werden: So wurden mittlerweile auch die Konferenzbeiträge der FORGE 2021 Konferenz - Forschungsdaten in den Geisteswissenschaften sowie der durch die DHd-Community organisierten virtuellen vDHd Konferenz 2021 über die beschriebenen Workflows und Prozesse als Einzelpublikationen auf Zenodo publiziert werden.41, 42, 43
Wenngleich die Entwicklung und Umsetzung der hier beschriebenen Vorverarbeitungs- und Publikationsprozesse als grundsätzliche Verbesserung der Publikationsstrategie des DHd-Verbands verstanden werden können, gibt es noch weitere Herausforderungen, die in der zukünftigen Arbeit des DHd Data Stewards angegangen werden sollen: Neben der kontinuierlichen Integration von Normdaten zur persistenten Identifikation und Referenzierbarkeit von bspw. Personen und Einrichtungen in den TEI-XML-Dateien sowie den Metadaten zu den Konferenzbeiträgen bedarf es auch einer Optimierung von Zitationsstil und Bibliografieangaben orientiert an aktuellen Community-Standards.
Vor dem Hintergrund, dass insbesondere der in diesem Beitrag beschriebene Einreichungsprozess für Konferenzbeiträge auf DHd-Jahreskonferenzen einerseits aus Nutzer*innen-Perspektive umständlich und wenig intuitiv gestaltet ist und andererseits das aus diesem Prozess generierte TEI-XML i.d.R. grundsätzliche manuelle Bereinigungen erfordert, gilt es auch diesen Prozess zu überprüfen und potenzielle Tools zur Optimierung zu evaluieren.44
Darüber hinaus gibt es einen Bedarf, eine grundsätzliche Dokumentation des gesamten Publikationsprozesses inklusive der Vorarbeiten für die Erstellung eines Book of Abstracts zu forcieren, um die Umsetzung im Rahmen zukünftiger DHd-Jahreskonferenzen zu erleichtern.
Literaturverzeichnis
- Andorfer, Peter; Cremer, Fabian; Steyer, Timo: DHd 2019 Book of Abstracts Hackathon, Frankfurt & Mainz 2019. Online: <http://doi.org/10.5281/zenodo.4622102>.
- Andorfer, Peter; Busch, Anna; Cremer, Fabian u.a.: Bericht zur vDHd2021-Veranstaltung. Zukunftslabor DHd-Abstracts, DHd-Blog, 08.05.2021. Online: <https://dhd-blog.org/?p=15980>, Stand: 02.05.2022.
- Burr, Elisabeth (Hg.): DHd 2016 Modellierung – Vernetzung – Visualisierung. Die Digital Humanities als Fächerübergreifendes Forschungsparadigma, Leipzig 2017. Online: <http://doi.org/10.5281/zenodo.3679331>.
- Busch, Anna; Cremer, Fabian; Lordick, Harald u.a.: Strukturen und Impulse zur Weiterentwicklung der DHd-Abstracts, Potsdam 2022. Online: <https://doi.org/10.5281/zenodo.6328089>.
- Cremer, Fabian: Nun sag, wie hältst Du es mit dem Digitalen Publizieren, Digital Humanities?, Digitale Redaktion, 2018. Online: <https://editorial.hypotheses.org/113>, Stand: 06.07.2021.
- Gebhard, Henning: Fidus Writer als Alternative zum DH ConValidator? Ein Prototyp, Potsdam 2022. Online: <http://doi.org/10.5281/zenodo.6327991>.
- Geierhos, Michaela (Hg.): DHd 2022 Kulturen des digitalen Gedächtnisses. Konferenzabstracts, Potsdam 2022. Online: <https://doi.org/10.5281/zenodo.6304590>.
- Hannesschläger, Vanessa; Andorfer, Peter: Menschen gendern? Einige Gedanken über Datenmodellierung zur Erhebung von Geschlechterverteilung anhand der TEI2016 Abstracts App, Köln 2018. Online: <https://doi.org/10.5281/zenodo.4622405>.
- Sahle, Patrick (Hg.): DHd 2019 Digital Humanities: multimedial & multimodal. Konferenzabstracts, Frankfurt & Mainz 2019. Online: <https://doi.org/10.5281/zenodo.2596095>.
- Schöch, Christof (Hg.): DHd 2020 Spielräume. Digital Humanities zwischen Modellierung und Interpretation. Konferenzabstracts, Paderborn 2020. Online: <https://doi.org/10.5281/zenodo.3666690>.
- Steyer, Timo; Andorfer, Peter; Cremer, Fabian: Abstract Enhancement. Potentiale der DHd-Konferenzabstracts als Daten/Publikation, Paderborn 2020. Online: <http://doi.org/10.5281/zenodo.4621706>.
- Stiegler, Johannes (Hg.): DHd 2015 Von Daten zu Erkenntnissen. Digitale Geisteswissenschaften als Mittler zwischen Information und Interpretation. Book of Abstracts, Graz 2015. Online: <https://dhd2015.uni-graz.at/de/nachlese/book-of-abstracts/>, Stand: 22.07.2022.
- Stolz, Michael (Hg.): DHd 2017 Digitale Nachhaltigkeit. Konferenzabstracts, Bern 2017. Online: <http://doi.org/10.5281/zenodo.3684825>.
- Vogeler, Georg (Hg.): DHd 2018 Kritik der digitalen Vernunft, Köln 2018. Online: <http://doi.org/10.5281/zenodo.3684897>.
- Wilkinson, Mark D.; Dumontier, Michel; Aalbersberg, IJsbrand Jan u.a.: The FAIR Guiding Principles for scientific data management and stewardship, in: Scientific Data 2016 (3). Online: <https://doi.org/10.1038/sdata.2016.18>.
1 Sahle, Patrick (Hg.): DHd 2019 Digital Humanities: multimedial & multimodal. Konferenzabstracts, Vorwort, Frankfurt & Mainz 2019. Online: <https://doi.org/10.5281/zenodo.2596095>.
2 Die im Book of Abstracts publizierten Beiträge stellen eine Zwischenform dar. Sie sind weder kurze Zusammenfassungen noch voll über-/ausgearbeitete Konferenzbeiträge i.S.v. Proceedings. Es handelt sich um die eingereichten und begutachteten Abstracts zur Konferenz mit einem durchschnittlichen Umfang zwischen 500 und 2000 Wörtern. In diesem Sinne erscheint die historisch bedingte Benennung der Publikationsform als „Book of Abstracts“ irreführend. Es gibt Bestrebungen innerhalb der DHd-Community, das Book of Abstracts zu einem umfangreicheren Proceedings-Band auszubauen, was in dem vorliegenden Beitrag allerdings nicht problematisiert wird. Trotz dieser begrifflichen Ungenauigkeit werden die in den Books of Abstracts publizierten Texte im Folgenden als Konferenzbeiträge bezeichnet.
3 Schöch, Christof (Hg.): DHd 2020 Spielräume. Digital Humanities zwischen Modellierung und Interpretation. Konferenzabstracts, Vorwort, Paderborn 2020. Online: <https://doi.org/10.5281/zenodo.3666690>.
4 Wilkinson, Mark D.; Dumontier, Michel; Aalbersberg, IJsbrand Jan u.a.: The FAIR Guiding Principles for scientific data management and stewardship, in: Scientific Data 2016 (3). Online: <https://doi.org/10.1038/sdata.2016.18>.
5 Digital Humanities im deutschsprachigen Raum, <https://dig-hum.de/>, Stand: 12.05.2022; Website zur DHd-Jahreskonferenz 2020 in Paderborn, <https://dhd2020.dig-hum.de/>, Stand: 12.05.2022.
6 DHd Data Steward, <https://dig-hum.de/dhd-data-steward>, Stand: 19.08.2022.
7 Website zur DHd Unconference 2012 in Hamburg, <https://dig-hum.de/dhd-gr%C3%BCndung-2012>, Stand: 12.05.2022.
8 Satzung des DHd-Verbands, <https://dig-hum.de/dhd-satzung>, Stand: 12.05.2022; Der Vorstand des DHd-Verbands, <https://dig-hum.de/dhd-vorstand>, Stand: 12.05.2022.
9 European Association of Digital Humanities, <https://eadh.org/>, Stand: 12.05.2022; Alliance of Digital Humanities Organizations, <https://adho.org/>, Stand: 12.05.2022.
10 Siehe Stiegler, Johannes (Hg.): DHd 2015 Von Daten zu Erkenntnissen. Digitale Geisteswissenschaften als Mittler zwischen Information und Interpretation. Book of Abstracts, Graz 2015. Online: <https://dhd2015.uni-graz.at/de/nachlese/book-of-abstracts/>, Stand: 22.07.2022; Burr, Elisabeth (Hg.): DHd 2016 Modellierung – Vernetzung – Visualisierung. Die Digital Humanities als fächerübergreifendes Forschungsparadigma, Leipzig 2017. Online: <http://doi.org/10.5281/zenodo.3679331>; Stolz, Michael (Hg.): DHd 2017 Digitale Nachhaltigkeit. Konferenzabstracts, Bern 2017. Online: <http://doi.org/10.5281/zenodo.3684825>; Vogeler, Georg (Hg.): DHd 2018 Kritik der digitalen Vernunft, Köln 2018. Online: <http://doi.org/10.5281/zenodo.3684897>; Sahle, Patrick (Hg.): DHd 2019 Digital Humanities: multimedial & multimodal. Konferenzabstracts, Frankfurt & Mainz 2019. Online: <https://doi.org/10.5281/zenodo.2596095>; Schöch, Christof (Hg.): DHd 2020 Spielräume: Digital Humanities zwischen Modellierung und Interpretation. Konferenzabstracts, Paderborn 2020. Online: <https://doi.org/10.5281/zenodo.3666690>; Geierhos, Michaela (Hg.): DHd 2022 Kulturen des digitalen Gedächtnisses. Konferenzabstracts, Potsdam 2022. Online: <https://doi.org/10.5281/zenodo.6304590>.
11 ConfTool, <https://www.conftool.net/de/startseite.html>, Stand: 12.05.2022.
12 ORCID, <https://orcid.org/>, Stand: 12.05.2022.
13 Taxonomy of Digital Research Activities in the Humanities (TaDiRAH), <https://de.dariah.eu/tadirah>, Stand: 30.03.2022.
14 Reviewer*innen, die Konferenzbeiträge für die DHd-Jahreskonferenzen begutachten, müssen vor Beginn des Review-Prozesses ihre fachliche Expertise auch anhand der TaDiRAH-Taxonomie angeben. Entsprechend wird die Vergabe von TaDiRAH-Kategorien für einen Konferenzbeitrag im Reviewprozess für die Zuordnung von Konferenzbeiträgen zu fachlich kompetenten Reviewer*innen genutzt.
15 DHConvalidator, <https://github.com/ADHO/dhconvalidator>, Stand: 13.05.2022.
16 Beispielstruktur für eine TEI-XML-Datei der DHd Jahreskonferenz 2020, <https://github.com/PatrickHelling/DHd_BoA-separated/blob/main/2020tei.xsd>, Stand: 05.05.2022.
17 Digital Humanities Conference 2013, <http://dh2013.unl.edu/>, Stand: 12.05.2022; TEI to PDF Skripte, <https://github.com/karindalziel/TEI-to-PDF>, Stand: 12.05.2022.
18 Siehe Burr 2017, Online <http://doi.org/10.5281/zenodo.3679331>; Stolz 2017, <http://doi.org/10.5281/zenodo.3684825>; Vogeler 2018, Online: <http://doi.org/10.5281/zenodo.3684897>; Sahle 2019, Online <https://doi.org/10.5281/zenodo.2596095>; Schöch 2020, Online: <https://doi.org/10.5281/zenodo.3666690>; Geierhos 2022, Online: <https://doi.org/10.5281/zenodo.6304590>.
19 DHd-Community auf Zenodo, <https://zenodo.org/communities/dhd/?page=1&size=20>, Stand: 12.05.2022.
20 Siehe Stiegler 2015, Online: <https://dhd2015.uni-graz.at/de/nachlese/book-of-abstracts/>, Stand: 22.07.2022.
21 Cremer, Fabian: Nun sag, wie hältst Du es mit dem Digitalen Publizieren, Digital Humanities?, Digitale Redaktion, 2018. Online: <https://editorial.hypotheses.org/113>, Stand: 06.07.2021.
22 Hannesschläger, Vanessa; Andorfer, Peter: Menschen gendern? Einige Gedanken über Datenmodellierung zur Erhebung von Geschlechterverteilung anhand der TEI2016 Abstracts App, Köln 2018. Online: <https://doi.org/10.5281/zenodo.4622405>.
23 Lordick, Harald: DH(d) Konferenzbeiträge, 2020, <http://www.steinheim-institut.de/dhd/>, Stand: 02.05.2022.
24 Andorfer, Peter: dhd-boas-app, 2019, <https://dhd-boas-app.acdh-dev.oeaw.ac.at/>, Stand: 02.05.2022.
25 Andorfer, Peter; Cremer, Fabian; Steyer, Timo: DHd 2019 Book of Abstracts Hackathon, Frankfurt & Mainz 2019. Online: <http://doi.org/10.5281/zenodo.4622102>; Steyer, Timo; Andorfer, Peter; Cremer, Fabian: Abstract Enhancement. Potentiale der DHd-Konferenzabstracts als Daten/Publikation, Paderborn 2020. Online: <http://doi.org/10.5281/zenodo.4621706>; Andorfer, Peter; Busch, Anna; Cremer, Fabian u.a.: Bericht zur vDHd2021-Veranstaltung. Zukunftslabor DHd-Abstracts, DHd-Blog, 08.05.2021, Online: <https://dhd-blog.org/?p=15980>, Stand: 02.05.2022; Busch, Anna; Cremer, Fabian; Lordick, Harald u.a.: Strukturen und Impulse zur Weiterentwicklung der DHd-Abstracts, Potsdam 2022. Online: <https://doi.org/10.5281/zenodo.6328089>.
26 Wilkinson, Mark D.; Dumontier, Michel; Aalbersberg, IJsbrand Jan u.a. 2016, Online: <https://doi.org/10.1038/sdata.2016.18>.
27 Zenodo Dokumentation, <https://developers.zenodo.org/>, Stand: 12.05.2022.
28 DataCite Metadatenschema, <https://schema.datacite.org/meta/kernel-4.3/>, Stand: 12.05.2022.
29 TEI-XML-Dateien zur DHd-Jahreskonferenz 2016, <https://github.com/stefaniegehrke/dhd2016-boa>, Stand: 31.03.2022; TEI-XML-Dateien zur DHd-Jahreskonferenz 2018, <https://github.com/GVogeler/DHd2018>, Stand: 31.03.2022; TEI-XML-Dateien zur DHd-Jahreskonferenz 2020, <https://github.com/NinaSeemann/DHd2020-BoA>, Stand: 31.03.2022. Das Repositorium mit den TEI-XML-Dateien zur DHd-Jahreskonferenz 2019 steht mittlerweile nicht mehr zur Verfügung.
30 Skripte für Einzel-PDF, <https://github.com/PatrickHelling/DHd_BoA-separated>, Stand: 12.05.2022.
31 Die TEI-XML-Dateien wurden bei ihrer Erstellung innerhalb des Einreichungsprozesses nach dem jeweiligen xml:id-Attribut benannt.
32 Skripte für Metadaten, <https://github.com/reborg789/zenodup>, Stand: 09.05.2022.
33 Der Attributinhalt wird i.d.R. automatisch aus dem ConfTool generiert. Bei einigen DHd-Jahreskonferenzen beginnt der Wert mit einer numerischen ID (bspw. „145_Helling_Der_DHd_Data_Steward”). Da ein Attribut, das mit numerischen Ziffern beginnt, in diesem Fall nicht valide ist, musste das xml:id-Attribut für die Verarbeitung entsprechend entfernt werden.
34 2020er Metadaten-Liste, <https://github.com/reborg789/zenodup/blob/main/2020metadata.xsd>, Stand: 05.05.2022.
35 Zenodup Skripte, <https://github.com/cceh/zenodup> Stand: 09.05.2022.
36 Über die Deposition IDs können die Uploads über die Zenodo REST API gelöscht, publiziert oder eine Übersicht der Deposits erstellt werden. Siehe Zenodo REST API Dokumentation, <https://developers.zenodo.org/#introduction>, Stand: 25.03.2022.
37 GitHub-Repositorium zur DHd-Jahreskonferenz 2014, <https://github.com/DHd-Verband/DHd-Abstracts-2014>, Stand: 05.04.2022; GitHub-Repositorium zur DHd-Jahreskonferenz 2015, <https://github.com/DHd-Verband/DHd-Abstracts-2015>, Stand: 05.04.2022; GitHub-Repositorium zur DHd-Jahreskonferenz 2016, <https://github.com/DHd-Verband/DHd-Abstracts-2016>, Stand: 05.04.2022; GitHub-Repositorium zur DHd-Jahreskonferenz 2017, <https://github.com/DHd-Verband/DHd-Abstracts-2017>, Stand: 05.04.2022; GitHub-Repositorium zur DHd-Jahreskonferenz 2018, <https://github.com/DHd-Verband/DHd-Abstracts-2018>, Stand: 05.04.2022; GitHub-Repositorium zur DHd-Jahreskonferenz 2019, <https://github.com/DHd-Verband/DHd-Abstracts-2019>, Stand: 05.04.2022; GitHub-Repositorium zur DHd-Jahreskonferenz 2020, <https://github.com/DHd-Verband/DHd-Abstracts-2020>, Stand: 05.04.2022.
38 Geierhos 2022, Online: <https://doi.org/10.5281/zenodo.6304590>.
39 DHd-Zenodo-Community, <https://zenodo.org/communities/dhd/?page=1&size=20>, Stand: 09.05.2022.
40 Digital Bibliography & Library Project (DBLP), <https://dblp.org/db/conf/dhd/index.html>, Stand: 12.05.2022; Index of Digital Humanities Conferences, <https://dh-abstracts.library.cmu.edu/conference_series/30>, Stand: 12.05.2022.
41 Sowohl bei der FORGE 2021 Konferenz als auch bei der vDHd Konferenz 2021 standen keine TEI-XML-Dateien als Datenbasis zur Verfügung. Entsprechend mussten die jeweiligen Metadaten zu den Konferenzbeiträgen manuell in eine Gesamt-Metadatendatei geschrieben werden. Die Generierung einzelner Metadaten-Dateien im JSON-Format für jeden Konferenzbeitrag konnten wiederum automatisch umgesetzt werden. Publiziert wurden schließlich die einzelnen Konferenzbeiträge im PDF-Format.
42 FORGE 2021, <https://forge2021.uni-koeln.de/>, Stand: 17.05.2022; vDHd 2021, <https://vdhd2021.hypotheses.org/>, Stand: 17.05.2022.
43 FORGE-Zenodo-Community, <https://zenodo.org/communities/forge/?page=1&size=20,> Stand: 17.05.2022; DHd-Zenodo-Community, <https://zenodo.org/communities/dhd/?page=1&size=20>, Stand: 17.05.2022.
44 Fidus Writer, <https://www.fiduswriter.org/>, Stand: 12.05.2022; Gebhard, Henning: Fidus Writer als Alternative zum DH ConValidator? Ein Prototyp, Potsdam 2022, Online: <http://doi.org/10.5281/zenodo.6327991>,
