
Kooperative Fachreferate
Eine offene Toolbox für den Bestandsaufbau
Zusammenfassung
Die Fachreferent*innen der SUB Göttingen entwickeln eine Toolbox für den Bestandsaufbau, um aus verschiedensten Datenquellen Titel semi-automatisiert zu selektieren. Für die Entwicklung solcher Tools bzw. Skripte sind IT-Kenntnisse nötig, die im Fachreferat momentan nicht unbedingt vorhanden sind. Verbesserte Aus- und Weiterbildungsinhalte (wie bspw. Library Carpentry) können helfen, diese Kenntnisse zu fördern. Zugleich ist eine Kultur der Kooperation und Arbeitsteilung zwischen den Fachreferent*innen nötig, um vermehrt digitale Tools anwenden und gemeinsam weiterentwickeln zu können.
Summary
The subject librarians of the SUB Göttingen have created a toolbox for the collection development in order to select books semi-automatically from various data sources. The design of such tools or scripts requires IT skills, which are not necessarily present amongst subject librarians at the moment. Improved education and further training (such as Library Carpentry) can help foster these skills. At the same time, a culture of cooperation and division of labour between the subject librarians is necessary in order to make more use of digital tools and develop them together.
1. Einleitung
Während die fachlichen Diskussionen rund um die wissenschaftlichen Dienstleistungen (und mithin die Tätigkeit von Fachreferent*innen) von Bibliotheken stark um verschiedene Themen(-Felder) kreisen, die unter dem Label „forschungsnahe Dienste“ zusammengefasst werden können,1 wollen wir uns im Folgenden dem Bestandsaufbau als einer traditionellen Kernaufgabe des Fachreferats widmen. Anhand eines Beispiels aus der Praxis zeigen wir, wie semi-automatisierte, IT-unterstützte Workflows dazu beitragen können, den Bestandsaufbau qualitativ zu verbessern und zugleich effizienter zu gestalten.
In Abschnitt 2 werden die Fachreferats-Toolbox der SUB Göttingen und verschiedene Anwendungsbeispiele für den Bestandsaufbau vorgestellt. Anschließend arbeiten wir heraus, welche IT-Kompetenzen Fachreferent*innen benötigen, um die dargestellten Techniken implementieren, adaptieren und nachnutzen zu können. Einen wichtigen Bezugsrahmen bildet hierbei das Core Curriculum von Library Carpentry (Abschnitt 3). Daran anschließend nehmen wir die Ausbildungsinhalte im Referendariat bzw. in den Library and Information Science-Studiengängen (MALIS) in den Blick und prüfen, inwieweit entsprechende IT-Kompetenzen hier Berücksichtigung finden (Abschnitt 4). In Abschnitt 5 versuchen wir, die beobachteten Diskrepanzen konstruktiv aufzulösen.
2. Computergestützter Bestandsaufbau
Durch das stets wachsende Angebot digitaler Informationen werden Erwerbungsentscheidungen zunehmend komplexer. Daher meinen wir, dass neue Wege in Richtung eines computergestützten Bestandsaufbaus etabliert werden sollten.
In den folgenden Ausführungen wird ein Workflow für den computergestützten Bestandsaufbau vorgestellt, der im Kreis der Fachreferent*innen der SUB Göttingen entstanden ist. Wir möchten verschiedene Arbeitsprozesse beim Bestandsaufbau vorstellen und zeigen, wie diese durch die neuen Skripte effizienter bearbeitet werden können. Dafür verwenden wir Funktionen der Fachreferats-Toolbox, ein GitHub-Repositorium (siehe Abbildung 1)2 mit Python-Skripten, Jupyter Notebooks und Beispieldaten, die seit 2021 in den Fachreferaten der SUB Göttingen entwickelt werden (siehe Abbildung 2 und 3).3 Im Gegensatz zu anderen computergestützten Werkzeugen wie z.B. dem Digitalen Assistenten4 sind alle Inhalte unserer Toolbox – im Sinne von Open Science – frei nutzbar.
In Abbildung 2 werden verschiedene Szenarien dargestellt. Alle gehen von einem Input aus, der aus unterschiedlichen Quellen stammen kann: Angebote von Verlagen, Geschenkangebote von Privatpersonen oder Organisationen (bspw. Bibliotheken, Vereine oder Unternehmen), Tauschangebote von anderen Bibliotheken, Abgaben von kompletten Institutsbibliotheken, Bibliografien von Forschenden, Daten von externen Quellen wie Wikidata, Newsletter von Verlagen etc. Folgend werden die genauen Schritte des Workflows erläutert.
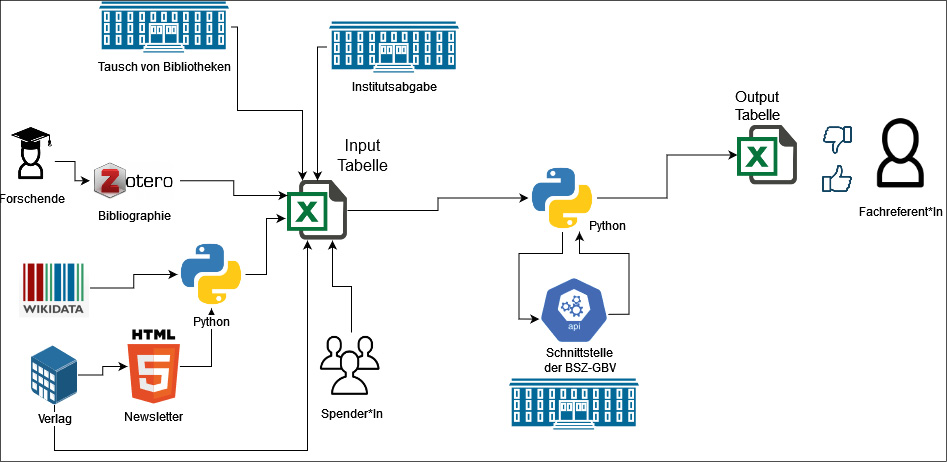
Damit der in Abbildung 2 skizzierte Workflow Anwendung finden kann, müssen drei Voraussetzungen erfüllt sein:
- Die Daten müssen in strukturierter Form vorliegen (JSON, XML, oder tabellarisch bspw. als Excel-Datei), am besten mit Identifikatoren versehen (ISBN, Pica-Produktionsnummer bzw. PPN).
- Die Datenquellen (wie bspw. Verbundkataloge, aber auch Datenquellen von Anbietenden) müssen offen zugänglich sein (via APIs, Repositorien).
- Die Fachreferent*innen müssen in der Lage sein, für sie speziell entwickelte Programme oder Skripte anzuwenden und somit IT-Kenntnisse besitzen.
Dass wir in Abbildung 2 von einer Tabelle als Input-Dokument ausgehen, liegt nicht daran, dass wir dieses Format für optimal halten. Vielmehr ist dieses Format eine pragmatische Lösung im Vergleich zu JSON oder XML-Dokumenten. Auch wenn die ursprünglichen Daten in strukturierter oder semi-strukturierter Form vorliegen, ist in der Mehrheit der Fälle eine gewisse Aufbereitung (händisch oder computergestützt) erforderlich.5
2.1 Datenangebote in Form von Tabellen (Verlagsangebote, Tausch, Spenden)
Um die von uns entwickelten Skripte zu erläutern, stellen wir unterschiedliche Anwendungsfälle vor. Das erste Beispiel ist ein Angebot in Tabellenform des Verlags SpringerNature. Solche Tabellen mit mehreren tausend Titeln können direkt über die Springer-Website heruntergeladen werden.6 Bevor Erwerbungsentscheidungen getroffen werden können, muss geprüft werden, welche Titel sich bereits im Bestand der Bibliothek befinden.
Derartige Angebote in tabellarischer Form erfassen in der Regel einen Titel pro Zeile und enthalten Spalten für weitere Daten wie Titel, Namensangaben von Autor*innen, ISBN etc. Das Skript (siehe Abbildung 3 und Jupyter Notebook „Springer.ipynb“ im Repositorium) iteriert über jede Zeile und speichert die ISBN als Variable. Hier kommen die Schnittstellen (APIs) der Verbundzentrale (VZG) des Gemeinsamen Bibliotheksverbunds (GBV) ins Spiel (siehe Abbildung 2), und zwar die Schnittstelle, die den OPAC (Göttinger Universitätskatalog, GUK) und das Discovery-System (GöDiscovery) der SUB Göttingen speist. Anstatt jedoch auf einer Web-Oberfläche über den Browser zu navigieren, werden die Daten direkt über die API abgefragt, welche die Daten zu den Treffern in strukturierter Form (bspw. PICA-XML) liefert. Die genaue Suche über die API ist ähnlich wie eine Katalog-Suche, und zwar z.B.: „isb 978-3-8376-5925-2“.7
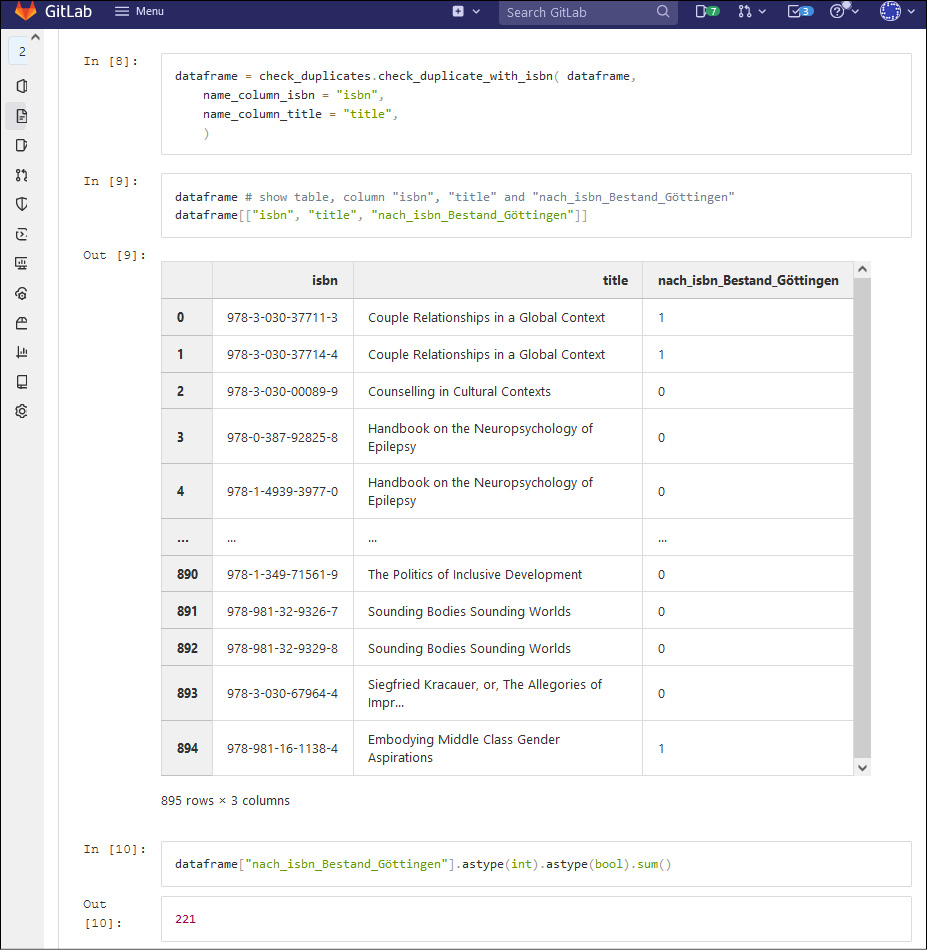
Aus den Daten der Treffer, welche die Schnittstelle zurückgibt, extrahiert das Skript nur diejenigen Daten, die wir als hilfreich für die endgültige Entscheidung erachten, wie z.B.:
- Anzahl von Exemplaren im Bestand
- Standort
- Medienart (Print oder E-Book)
Darüber hinaus kann das Skript andere Informationen aus der Datenbank des Katalogs K10plus extrahieren. Zum Beispiel können sich Fachreferent*innen darüber informieren, wie viele Bibliotheken des K10plus den betreffenden Titel im Bestand haben. Dies kann je nach Art des Titels eine wichtige Information für eine Kauf- oder Übernahmeentscheidung sein.
Durch die Abfragen wird die Ausgangstabelle des Verlags mit weiteren Spalten angereichert. Abschließend wird sie als Output-Tabelle gespeichert. Auf dieser Grundlage können die Fachreferent*innen nun ihre Erwerbungsentscheidungen treffen.
Andere Anwendungsfälle können ähnlich bearbeitet werden. In einigen Fällen werden Anpassungen nötig, z. B. wenn keine Identifikatoren wie ISBN vorhanden sind. Dafür haben wir bereits Funktionen für die Suche nach dem Titel und dem Nachnamen der Autorin oder des Autors bzw. der Herausgeberin oder des Herausgebers angelegt.
Damit diese Suchen möglich sind, müssen die ursprünglichen Daten in einem strukturierten Format vorliegen. Leider werden jedoch häufig Tauschlisten als Word- oder PDF-Dokumente versendet. Wir plädieren dafür, dass für die Tauschlisten zwischen Bibliotheken tabellarische Formate genutzt werden. Dabei sollten die Vor- und Nachnamen der Verfasser*innen gemäß der sog. „Tidy Data“-Prinzipien (siehe Sektion 3.2) in unterschiedlichen Spalten gelistet werden. Für die Verständigung auf einheitliche Datenformate wäre eine bibliotheksübergreifende Diskussion der involvierten Kolleg*innen zu diesem Thema zielführend.
Ein weiterer Anwendungsfall sind Spenden oder Abgaben von Sammlungen ohne Katalogisierung. Für diesen Fall steht ein Excel-Template zur Verfügung, in das die Spender*innen Titeldaten eintragen können.8 Dies ist oft nicht realisierbar und keine Voraussetzung für eine Prüfung oder Annahme der Spende durch die SUB Göttingen. Vorgeschlagen wird diese Verfahrensweise dennoch als eine mögliche Option.
2.2 Aktive Suche nach Datenangeboten für die Erwerbung (Bibliografien in Zotero, Wikidata, Newsletter)
Weitere Anwendungsfälle der Toolbox betreffen Input-Daten, die nicht bereits als Tabelle vorliegen. In diesen Fällen sind die Daten anders oder nicht strukturiert und die Fachreferent*innen stehen vor der Aufgabe, diese Daten selbst in Input-Tabellen umzuwandeln.
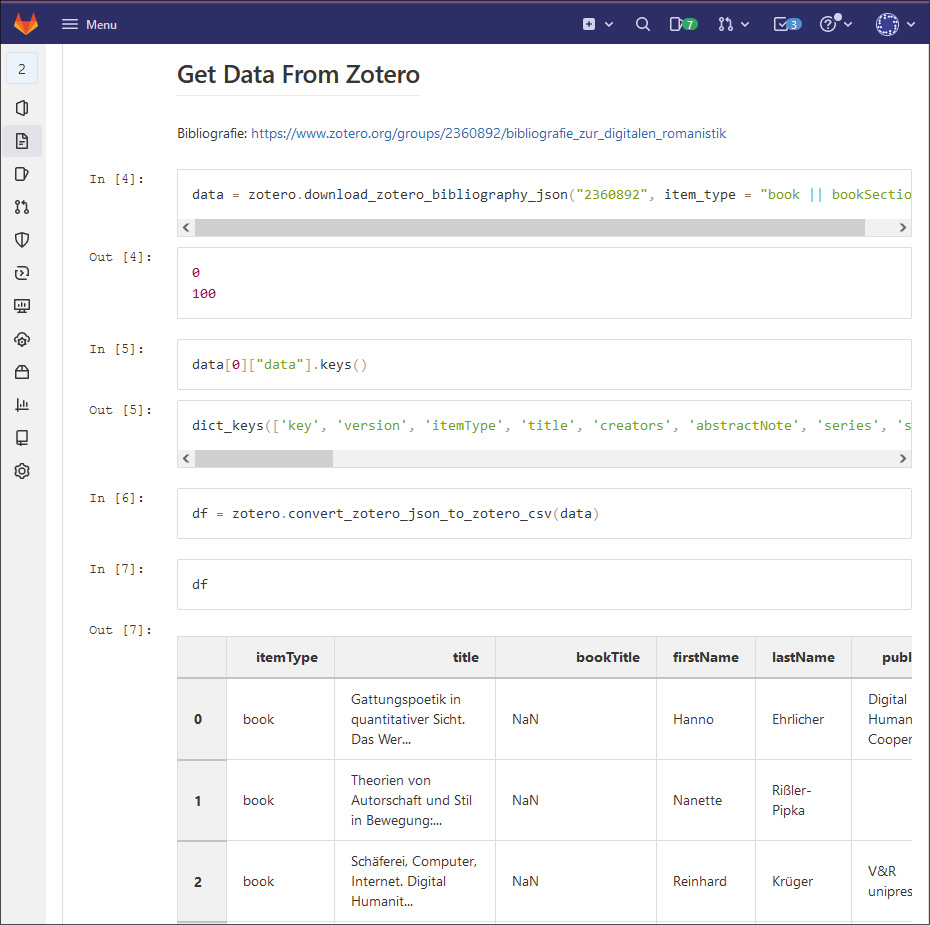
Ein mögliches Szenario bestünde darin, Referenzen aus externen Bibliografien zu extrahieren, die den Bibliotheksbestand zu bereichern versprechen. Auf diese Weise können Bibliotheken auf die Angebote von Open Science Initiativen zurückgreifen, die offene Bibliografien führen (z.B. über Fachbibliografien in Plattformen wie Zotero, siehe Abbildung 4). Damit würde die Bibliothek eine proaktive, forschungsnahe Rolle übernehmen, indem sie Forschenden aktiv „zuhört“. Derartige Datenangebote für die Erwerbung sind zudem unabhängig vom Marketing der Verlage und durch die unmittelbare Prägung durch die Forschung besonders wertvoll. Im Bereich der Digital Humanities bspw. gibt es zahlreiche Bibliografien, die seit Jahren gepflegt werden, etwa zu Stilometrie,9 Digitaler Geschichtswissenschaft10 oder zur Einführung in die Digital Humanities.11 Im begleitenden Repositorium für die vorliegende Publikation ist ein Jupyter Notebook („zotero.ipynb“) zu finden, in dem wir eine dieser Bibliografien nutzen, um die Daten aus der API von Zotero zu sammeln, in eine Tabelle zu überführen und diese mit dem Bestand der SUB Göttingen abzugleichen.
Eine dritte Möglichkeit besteht darin, Datenquellen zu nutzen, die strukturiert und offen online vorliegen. Zum Beispiel können die Daten von Wikidata auch für die Erwerbung verwendet werden. In einem ersten Schritt muss dazu ein Filter-Kriterium ausgewählt werden, zum Beispiel Autor*innen, die einen Preis gewonnen haben. Der Nobelpreis hat z.B. die Wikidata-Kennung Q37922. Dieses Kennzeichen nutzen wir für eine Query12 (Jupyter Notebook „wikidata.ipynb“ im Repositorium), um alle Autor*innen, die den Nobelpreis gewonnen haben, und die von ihnen geschriebenen Werke zu extrahieren. Natürlich können die Fachreferent*innen sich für andere Preise interessieren, die für ihre Fächer relevante Kriterien betreffen oder solche, die fächerübergreifend von Interesse sind, wie etwa Diversität.13 Dazu müsste im Skript entsprechend die Wikidata-Kennung des Preises bzw. Kriteriums angepasst werden.
Die letzte Art von Quellen, die wir betrachten, sind online-Newsletter. Wenn für jeden Titel des Newsletters eine ISBN angezeigt wird, kann das Browser-Plugin „AutoLink“ von Bernhard Tempel verwendet werden.14 Wenn der Newsletter nicht online erscheint, kann die E-Mail des Newsletters als HTML-Dokument lokal gespeichert werden. Anschließend können die Daten daraus extrahiert und in eine Tabelle überführt werden. Dafür werden Technologien wie sog. „Reguläre Ausdrücke“, xPaths15 und weitere Python-Libraries16 benötigt. Im Repositorium ist bereits ein Skript für Newsletter aus dem Bereich der Kunstgeschichte hinterlegt (Jupyter Notebook „froelichundkaufmann.ipynb“). Wie in den vorigen Beispielen werden die Daten eingelesen, mit dem Bestand der SUB Göttingen abgeglichen und eine Output-Tabelle erstellt.
3. IT-Kenntnisse von Fachreferent*innen und Library Carpentry als passgenaue Fortbildung
3.1 IT-Kenntnisse
Aus den bisherigen Ausführungen dürfte klargeworden sein, dass grundlegende Programmierkenntnisse sowie eine gute Kenntnis der Geschäftsgänge und der Bibliotheksinfrastruktur nötig sind, um Skripte wie die vorgestellten selbst zu erstellen oder an neue Szenarien anzupassen. Python und Jupyter Notebooks, Git, Reguläre Ausdrücke oder die Unix Shell sind Techniken, die nicht jede*r beherrscht. Unserer Meinung nach ist dies aber auch nicht unbedingt nötig. Die unterschiedlichen Level von IT-Kenntnissen bei Fachreferent*innen legen vier mögliche Rollen nahe, die Fachreferent*innen bei der Arbeit mit der Toolbox einnehmen können:
- Gruppe 1: Die Anwender*innen
- Gruppe 2: Die Adaptierenden
- Gruppe 3: Die Programmierer*innen
- Gruppe 4: Die Entwickler*innen
Für die Gruppe 1 der Anwender*innen, die die Skripte zur Deduplizierung von Angeboten lediglich nutzen, wurde an der SUB Göttingen eine Schritt-für-Schritt-Anleitung erstellt, mit der alle Fachreferent*innen die Dublettenkontrolle durch die Anreicherung von Tabellen selbst durchführen können. Die verwendeten Techniken (Python, Jupyter, Shell, Git) werden in der Anleitung als „Black Boxes“ behandelt und nicht näher erläutert. In mehreren internen Workshops wurde die Umsetzung dieser Anleitung eingeübt. Die Nutzung dieser Skripte erfordert also keine Programmierkenntnisse, sondern lediglich die Bereitschaft, sich auf neue Technologien einzulassen. Durch die Workshops zur Toolbox kann etwa die Hälfte der Fachreferent*innen der SUB Göttingen zu den Anwender*innen gezählt werden. So verteilt sich die Deduplizierung von Angeboten jetzt auf mehrere Schultern bzw. viele Fachreferent*innen können ihre Datenanalysen nun selbst durchführen.
Die Adaptierenden (Gruppe 2) sind in der Lage, vorhandene Skripte für neue Anwendungen anzupassen. Diese Anpassungen erfordern Grundkenntnisse in unterschiedlichen Programmen, Datenformaten und Programmiersprachen. Library Carpentry, ein Set von Kursen, auf das wir noch näher eingehen, bietet eine gute Möglichkeit, sich diese Grundlagen anzueignen. Zurzeit zählt eine Fachreferentin zu den Adaptierenden.
Unter Programmierer*innen (Gruppe 3) verstehen wir Personen, die Erfahrungen in einigen Programmiersprachen haben und die einfache Skripte für sich oder für eine kleine Gruppe schreiben können. Programmierer*innen in diesem Sinne sind bisher noch selten in den Fachreferaten, sie können allerdings enorm hilfreich für das Team sein. Adaptierende können durch Übung und Weiterbildung zu Programmierer*innen werden. Gezielte Angebote zur Weiterbildung sind z.B. die European Summer University in Digital Humanities17 oder die Lektionen von The Programming Historian.18 Der Programmierer der Toolbox ist selbst Fachreferent der SUB Göttingen.
Unter Entwickler*innen (Gruppe 4) verstehen wir erfahrene IT-Fachleute, die mehrere Programmiersprachen beherrschen und Projekte für eine größere Gruppe technisch umsetzen können. Diese Personen sind normalerweise nicht als Fachreferent*innen angestellt, vielmehr ist diese Rolle entweder bei Bibliotheksverbünden oder (bei größeren Bibliotheken) in z.B. IT-Abteilungen angesiedelt. Für anspruchsvolle Projekte können die Entwickler*innen in Bibliotheksverbünden oder IT-Abteilungen die Arbeit der Fachreferate unterstützen. An der SUB Göttingen sind im Fachreferat keine Entwickler*innen vertreten. Programmierer*innen und Entwickler*innen der SUB Göttingen arbeiten jedoch in Projekten (z.B. FIDs) mit den Fachreferent*innen zusammen.
3.2 Library Carpentry als passgenaue Fortbildung
Die Lektionen eines mehrtägigen Library Carpentry-Workshops19 decken die benötigten Grundkenntnisse ab, um selbst Skripte für eigene Bedürfnisse adaptieren zu können. Inhaltlich werden Reguläre Ausdrücke, die Unix Shell, Open Refine und eine Einführung zu Git behandelt. Ein erweitertes Curriculum enthält Kurse zu SQL und Tidy Data. Weitere Inhalte befinden sich noch in der Erprobung. Diese Themen decken sich mit den IT-Kompetenzen, die für die Entwicklung der oben beschriebenen Toolbox benötigt werden. Die Teilnahme an einem Kurs ist aber nicht ausreichend, um eigenständig komplexe Werkzeuge zu entwickeln. Ein Workshop bietet jedoch ein gutes Grundverständnis, um bestehende Skripte nachzuvollziehen und durch ein erlerntes „Computational Thinking“ (auf Deutsch etwa: informatisches Denken) eigene Ideen zu formulieren.20 Im Team, zusammen mit Programmierer*innen, kann so aus einer Idee ein neues Konzept und schließlich ein neues Werkzeug für die Toolbox entstehen. Auch Projekte in anderen Bibliothekskontexten, die von Entwickler*innen durchgeführt werden, lassen sich mit diesen Grundkenntnissen konstruktiv begleiten. Da keine Vorkenntnisse erwartet werden, können also besonders Personen der oben beschriebenen Gruppe 1 (Anwender*innen) über einen Carpentry-Workshop die nötigen Grundlagen erlernen, um zu den Adaptierenden (Gruppe 2) „aufzusteigen“. Adaptierende, die sich zu Programmierer*innen (Gruppe 3) weiterbilden möchten, finden in den Carpentry-Workshops ebenso viele wesentliche Inhalte.
Die Lektionen von Library Carpentry werden von einer weltweiten Community gepflegt sowie strukturiert weiterentwickelt. Der weltweit erste Library Carpentry-Workshop wurde 2015 durchgeführt,21 in Deutschland fand der erste Library Carpentry-Workshop 2018 statt, ausgerichtet vom VDB Landesverband Hessen.22 Seit 2018 ist die SUB Göttingen Mitglied bei den Carpentries und bildet zertifizierte Carpentry Instructors aus (darunter auch Fachreferent*innen). Seit 2019 werden Carpentry-Workshops sowohl SUB-intern als auch extern für die Nutzer*innen der Bibliothek durchgeführt. Auch in der Library Carpentry Advisory Group bzw. als Maintainerin in der Library Carpentry Community sind Mitarbeiterinnen der SUB Göttingen aktiv. Motiviert durch die Nutzung der Deduplizierungsskripte fand Anfang März 2022 ein einwöchiger Library Carpentry-Workshop in der SUB Göttingen statt, der speziell auf die Bedürfnisse der Fachreferent*innen zugeschnitten wurde.
4. IT-Kompetenzen in der Ausbildung für den höheren Bibliotheksdienst
Auch wenn die beruflichen Hintergründe von Fachreferent*innen sehr heterogen sind, gibt es mit dem Referendariat (bzw. Volontariat in einigen Bundesländern) weiterhin einen klassischen Ausbildungsweg für dieses Berufsfeld. Referendar*innen belegen neben der berufspraktischen Ausbildung in ihrer jeweiligen Bibliothek ein MALIS-Studium (Master of Arts in Library and Information Science) am Institut für Bibliotheks- und Informationswissenschaft (IBI) der Humboldt-Universität zu Berlin23 oder werden für die bibliothekstheoretische Ausbildung an die Bibliotheksakademie Bayern (München) entsandt.24
Das IBI bietet den MALIS-Studiengang zudem als weiterbildenden Studiengang für sog. „freie Studierende“ an. Dies können Personen sein, die bisher nicht im Bibliotheksbereich tätig sind, aber auf diese Weise quereinsteigen wollen. Viele freie Studierende arbeiten hingegen bereits im Bibliotheksbereich und haben ursprünglich bspw. die FAMI-Ausbildung absolviert oder einen einschlägigen Bachelor-Studiengang abgeschlossen.25 Neben dem IBI bieten auch einige andere Hochschulen berufsbegleitende MALIS-Studiengänge26 oder MA-Studiengänge mit ähnlichen Inhalten an,27 wobei nur ein Teil dieser Studiengänge mit dem MALIS des IBI bzw. dem Referendariat vergleichbar ist.
Ohne an dieser Stelle eine detaillierte Analyse des MALIS-Studiengangs am IBI bzw. der theoretischen Referendariatsausbildung leisten zu können, lassen sich doch einige Trends und Grundzüge beobachten. Vor allem ist festzuhalten, dass die Inhalte weiterhin generalistisch ausgerichtet sind. Neben bibliotheksbezogenen IT-Kenntnissen sind bspw. Rechtsthemen (u. a. Urheberrecht), Personalmanagement und -führung, Organisationsentwicklung, Inhaltserschließung und bibliotheksbauliche Fragen in den Curricula verankert.28 Zweitens lässt sich konstatieren, dass mehr Flexibilität in die Studiengänge integriert wird durch die Ausweitung von Wahlpflichtbereichen, deren Belegung den Studierenden auch eine vertiefte Beschäftigung mit IT-Themen ermöglicht. Verwiesen sei in diesem Zusammenhang auf den jüngst reakkreditierten MALIS-Studiengang der TH Köln,29 der seit 2009 explizit als Alternative zum Referendariat angeboten wird. Auch im MALIS-Studiengang am Berliner IBI können mittlerweile zwei Lehrveranstaltungen im Rahmen des Vertiefungsmoduls belegt werden.30 Als dritter Trend lässt sich beobachten, dass hinsichtlich der IT-Kompetenzen zunehmend Wert auf anwendungsorientiertes Wissen gelegt wird und dies die reine Vermittlung theoretischen Wissens in Form von Frontalunterricht ergänzt bzw. zurückdrängt. Diese Entwicklung zeigt sich ebenfalls am erwähnten MALIS-Studiengang der TH Köln, wo bereits im ersten Semester das Belegen einer Library Carpentry-Veranstaltung obligatorischer Teil des Grundlagenmoduls ist.31 Im MALIS-Studiengang des IBI kann eine Library Carpentry-Veranstaltung im Rahmen des Vertiefungsmoduls belegt werden; zudem wurde ein Selbstlernkurs „Grundlagen des Programmierens“ in die Studieneingangsphase integriert.32 Viertens und letztens sei darauf verwiesen, dass zunehmend spezialisierte (berufsbegleitende und weiterbildende) Studiengänge angeboten werden, die einen dezidierten Fokus auf IT-Kompetenzen legen. Beispielhaft genannt sei der Master-Studiengang Bibliotheksinformatik (M. Sc.) der TH Wildau.33
Es zeigt sich mithin, dass in den einschlägigen Studiengängen zunehmend Möglichkeitsräume für die vertiefte Auseinandersetzung mit IT-Inhalten geschaffen werden, die angehende Fachreferent*innen –
oder bereits als Fachreferent*innen tätige Personen, die einen berufsbegleitenden Studiengang belegen – nutzen können. Zugleich ist zu konstatieren, dass durch die weiterhin generalistische Ausrichtung der Ausbildungsinhalte sicherlich niemand zur Programmiererin oder zum Programmierer wird, wenn nicht vor Studienbeginn bereits grundlegende Kenntnisse vorhanden waren. Die Grundlagen dafür, dass (künftige) Fachreferent*innen bessere Anwendungsfähigkeiten erlangen können und im Sinne der in Abschnitt 3 geschilderten Gruppen in der Lage sind, Tools und Programme für ihre Zwecke anzuwenden, sind jedoch gelegt.
Gleichwohl ließe sich die Forderung aufstellen, dass angesichts des rasanten digitalen Wandels eine noch stärkere Berücksichtigung von IT-Themen in den vorgestellten Ausbildungswegen bzw. Studiengängen vorgenommen werden sollte. Dies wäre eine leicht zu stellende, aber unserer Ansicht nach auf gewisse Weise auch wohlfeile Forderung, und zwar v.a. aus folgenden Gründen: Es handelt sich beim Referendariat und den MALIS-Studiengängen nicht um eine Ausbildung im engeren Sinn für das Fachreferat. Ein Großteil der Absolvent*innen ist anschließend in anderen Bereichen tätig (bspw. Führungspositionen in öffentlichen Bibliotheken) oder erledigt nur anteilig Fachreferatsarbeit.34 Diese Heterogenität ist ein gutes Argument dafür, den generalistischen Anspruch im Referendariat und den MALIS-Studiengängen aufrecht zu erhalten. Zudem können Ausbildungs- und Studieninhalte nicht beliebig erweitert werden. Insofern sollten in einer ehrlichen Debatte Forderungen nach mehr IT-Schwerpunkten immer auch mit einer Aussage über zu streichende oder zumindest zu schwächende Inhalte verknüpft werden.35 Nicht zuletzt sind zu einem großen Teil Quereinsteiger*innen – mit unterschiedlichsten beruflich-biographischen Hintergründen – im Fachreferat tätig. Auch aus diesem Grund sollte ein stärkerer Fokus auf das Thema Fort- und Weiterbildung gelegt werden, statt sich einseitig mit Ausbildungsinhalten zu beschäftigen. Das Angebotsspektrum ist hier groß und reicht von Online-Selbstlernkursen über klassische ein- oder mehrtätige Workshops bis hin zu intensiven, mehrjährigen Programmen.36
5. Schlussfolgerungen
Die Aufgabendiversifizierung im Fachreferat sowie im höheren Bibliotheksdienst allgemein37 führt zu der Frage, wie Fachreferent*innen für ihre Aufgaben auch künftig gut gerüstet sein können. Wie wir am Beispiel der SUB-Toolbox zu zeigen versucht haben, ist es wichtig, dass sich die Inhalte von Aus-, Fort- und Weiterbildungen den sich wandelnden beruflichen Anforderungen anpassen. Dies allein jedoch wird der Herausforderung nicht gerecht.
David Tréfás wies in einem anregenden Artikel 2018 völlig zurecht darauf hin, dass es nur „schwer nachvollziehbar“ sei, „wie ein einzelner Fachreferent alle traditionellen und innovativen Aufgaben übernehmen soll“ und dass „die zunehmende Komplexität (...) die Möglichkeiten des Einzelnen bei Weitem“ übersteige.38 Daraus folgerte Tréfás, dass Fachreferent*innen stärker als Gruppe zusammenarbeiten müssten. Dem möchten wir uns explizit anschließen und für eine kooperative Arbeitskultur eintreten, die gerade dann gut funktionieren kann, wenn im Fachreferat spezialisierte Kolleg*innen mit unterschiedlichen Hintergründen, Expertisen und Interessensschwerpunkten tätig sind.39 Wenn bspw. zwei oder drei Kolleg*innen tiefergehende Programmierkenntnisse haben, um Tools wie die hier vorgestellten zu entwickeln, dann genügt es, wenn die übrigen Kolleg*innen ein solides Grundverständnis mitbringen, um diese Tools anzuwenden und ggf. die Weiterentwicklung konstruktiv zu begleiten.40
Grundvoraussetzung hierfür ist ein gewisses Maß an Offenheit im Kollegium und die Bereitschaft, eine durch Kooperation geprägte Arbeitskultur zu leben. Zugleich bedarf es einer vorausschauenden Personalplanung und -entwicklung, die sicherstellt, dass in den Teams Expert*innen für unterschiedliche Themen langfristig vertreten sind und Fachkenntnisse gezielt weiterentwickelt werden.
Literaturverzeichnis
- Andrews, Penny; Baker, James: The Programming Historian. Developing and sustaining impact in the Global South, Zenodo, 19.05.2020. Online: <https://doi.org/10.5281/zenodo.3813763>.
- Enderle, Wilfried: Selbstverantwortliche Pflege bibliothekarischer Bestände und Sammlungen. Zu Genese und Funktion wissenschaftlicher Fachreferate in Deutschland 1909–2011, in: Bibliothek. Forschung und Praxis 36 (1), 2012, S. 24–31. Online: <https://doi.org/10.1515/bfp-2012-0004>.
- Hinrichs, Imma; Milmeister, Gérard; Schäuble, Peter u. a.: Computerunterstützte Sacherschließung mit dem Digitalen Assistenten (DA-2), in: o-bib. Das offene Bibliotheksjournal 3 (4), 2016, S. 156–185. Online: <https://doi.org/10.5282/O-BIB/2016H4S156-185>.
- Horstmann, Wolfram; Jahn, Najko; Schmidt, Birgit: Der Wandel der Informationspraxis in Forschung und Bibliothek, in: Zeitschrift für Bibliothekswesen und Bibliographie 62 (2), 2015, S. 73–79. Online: <https://doi.org/10.3196/186429501562223>.
- Kraus, Eva: „Quo vadis, IBI-Fernstudent*in?“. Verbleibstudie für den Weiterbildenden Masterstudiengang Bibliotheks- und Informationswissenschaft im Fernstudium am Institut für Bibliotheks- und Informationswissenschaft (IBI) der Humboldt-Universität zu Berlin (Berliner Handreichungen zur Bibliotheks- und Informationswissenschaft, Bd. 447), Berlin 2020. Online: <https://doi.org/10.18452/21052>.
- Schmidt, Nora: Überlegungen für die Dekolonialisierung wissenschaftlicher Bibliotheken
in Europa, in: Young Information Scientist 6, 28.04.2021, S. 1–10. Online: <https://doi.org/
10.25365/yis-2021-6-1>. - Seidlmayer, Eva; Müller, Rabea; Förstner, Konrad U.: Data Literacy for Libraries. A Local Perspective on Library Carpentry. Preprint, 05.10.2020. Online: <https://doi.org/10.18452/22009>.
- Stille, Wolfgang; Farrenkopf, Stefan; Hermann, Sibylle u. a.: Forschungsunterstützung an Bibliotheken. Positionspapier der Kommission für forschungsnahe Dienste des VDB, in: o-bib. Das offene Bibliotheksjournal 8 (2), 2021, S. 1–19. Online: <https://doi.org/10.5282/o-bib/5718>.
- Tappenbeck, Inka; Meinhardt, Haike: MALIS Reloaded. Der berufsbegleitende Masterstudiengang „Bibliotheks- und Informationswissenschaft“ der TH Köln präsentiert sich mit einem neuen Curriculum, in: o-bib. Das offene Bibliotheksjournal 8 (2), 2021, S. 1–9. Online: <https://doi.org/10.5282/o-bib/5708>.
- Tappenbeck, Inka: Fachreferat 2020. From collections to connections, in: Bibliotheksdienst 49 (1),
2015, S. 37–48. Online: <https://doi.org/10.1515/bd-2015-0006>. - Tréfás, David: Das Fachreferat. Vom Universalgelehrten zur Schwarmintelligenz, in: Bibliotheks-
dienst 52 (12), 2018, S. 864–874. Online: <https://doi.org/10.1515/bd-2018-0103>.
1 Genannt seien exemplarisch die Themen Open Access und Forschungsdatenmanagement. Siehe hierzu Stille, Wolfgang; Farrenkopf, Stefan; Hermann, Sibylle u. a.: Forschungsunterstützung an Bibliotheken. Positionspapier der Kommission für forschungsnahe Dienste des VDB, in: o-bib. Das offene Bibliotheksjournal 8 (2), 2021, S. 1–19. Online: <https://doi.org/10.5282/o-bib/5718>, Stand: 19.11.2021.
2 <https://github.com/subugoe/Fachreferats-Toolbox>, Stand: 19.11.2021.
3 Jupyter Notebooks sind hybride Dokumente, die funktionierende Befehle in Programmiersprachen wie Python, das Ergebnis dieser Befehle sowie eine Dokumentation in einem einzelnen Dokument vereinen.
4 Hinrichs, Imma; Milmeister, Gérard; Schäuble, Peter u. a.: Computerunterstützte Sacherschließung mit dem Digitalen Assistenten (DA-2), in: o-bib. Das offene Bibliotheksjournal 3 (4), 2016, S. 156–185. Online: <https://doi.org/10.5282/O-BIB/2016H4S156-185>, Stand: 19.11.2021.
5 Zum Beispiel enthalten Tabellen oft mehrere ISBN für eine Publikation oder die Vor- und Nachnamen der Autor*innen sind in einer einzigen Spalte gespeichert.
6 <https://metadata.springernature.com/metadata/books>, Stand: 19.11.2021.
7 In der URL der API wird diese Suche wie folgt ausgedrückt: <http://sru.k10plus.de/opac-de-7!rec=1?version=1.1&query=pica.isb=%22978-3-8376-5925-2%22&operation=searchRetrieve&maximumRecords=10&recordSchema=picaxml>.
8 Ist eine ISBN vorhanden, müssen nur der Titel, der Name der Autorin oder des Autors (bzw. Hg.) und das Erscheinungsjahr eingetragen werden. Fehlt die ISBN, sollten zusätzlich Verlag und Erscheinungsort angegeben werden.
9 <https://www.zotero.org/groups/643516/stylometry_bibliography>, Stand: 19.11.2021.
10 <https://www.zotero.org/groups/2291669/digitale_geschichtswissenschaft>, Stand: 19.11.2021.
11 <https://www.zotero.org/groups/113737/doing_digital_humanities_-_a_dariah_bibliography>, Stand: 19.11.2021.
12 Diese Query ist als SPARQL-Query ausgedrückt, der Standard-Abfragesprache für Daten in Resource Description Framework-Formaten wie Wikidata.
13 Schmidt, Nora: Überlegungen für die Dekolonialisierung wissenschaftlicher Bibliotheken in Europa, in: Young Information Scientist 6, 28.04.2021, S. 1–10. Online: <https://doi.org/10.25365/yis-2021-6-1>, Stand: 19.11.2021.
14 <http://www.tempelb.de/autolink-tibub/>, Stand: 19.11.2021.
15 XPath is eine Standard-Abfragesprache für Daten in XML-Dokumenten.
16 Z.B. die Python-Library Beautiful Soup, die die Extraktion von Daten in HTML und XML ermöglicht.
17 <https://esu.fdhl.info/>, Stand: 19.11.2021.
18 Andrews, Penny; Baker, James: The Programming Historian. Developing and sustaining impact in the Global South, Zenodo, 19.05.2020. Online: <https://doi.org/10.5281/zenodo.3813763>, Stand: 05.11.2021.
19 <https://librarycarpentry.org/>, Stand: 19.11.2021.
20 Seidlmayer, Eva; Müller, Rabea; Förstner, Konrad U.: Data Literacy for Libraries. A Local Perspective on Library
Carpentry. Preprint, 05.10.2020. Online: <https://doi.org/10.18452/22009>, Stand: 07.11.2021.
21 Baker, James; Moore, Caitlin; Priego, Ernesto u. a.: Library Carpentry: software skills training for library professionals, in: LIBER Quarterly: The Journal of the Association of European Research Libraries 26/3 (2016), S. 141–162. Online: <https://doi.org/10.18352/lq.10176>, Stand: 19.11.2021.
22 <https://librarycarpentry.org/past_workshops/>, Stand: 19.11.2021.
23 <https://www.ibi.hu-berlin.de/de>, Stand: 19.11.2021.
24 <https://www.bsb-muenchen.de/kompetenzzentren-und-landesweite-dienste/ausbildung-fortbildung-jobs/bibliotheksakademie-bayern/>, Stand: 19.11.2021. Allgemein zu den Ausbildungswegen: Kraus, Eva: „Quo vadis, IBI-Fernstudent*in?“. Verbleibstudie für den Weiterbildenden Masterstudiengang Bibliotheks- und Informationswissenschaft im Fernstudium am Institut für Bibliotheks- und Informationswissenschaft (IBI) der Humboldt-Universität zu Berlin (Berliner Handreichungen zur Bibliotheks- und Informationswissenschaft, Bd. 447), Berlin 2020, Kap. 2.1. Online: <https://doi.org/10.18452/21052>, Stand: 19.11.2021.
25 Kraus 2020, u.a. S. 39–42, S. 93–96.
26 Z.B. die HTW Leipzig; siehe <https://www.htwk-leipzig.de/studieren/studiengaenge/masterstudiengaenge/biblio theks-und-informationswissenschaft/>, Stand: 19.11.2021.
27 Z.B. die HdM Stuttgart mit dem MA-Studiengang „Bibliotheks- und Informationsmanagement“; siehe <https://www.hdm-weiterbildung.de/berufsbegleitende-masterangebote/bibliotheks-und-informationsmanagement-master-of-arts>, Stand: 15.03.2022.
28 Siehe bspw. unter <https://www.bsb-muenchen.de/q4/>, Stand: 19.11.2021.
29 Tappenbeck, Inka; Meinhardt, Haike: MALIS Reloaded. Der berufsbegleitende Masterstudiengang „Bibliotheks- und Informationswissenschaft“ der TH Köln präsentiert sich mit einem neuen Curriculum, in: o-bib. Das offene Bibliotheksjournal 8 (2), 2021, S. 1–9, hier S. 5, 7–8. Online: <https://doi.org/10.5282/o-bib/5708/q4>, Stand: 21.01.2022.
30 Siehe hierzu <https://www.ibi.hu-berlin.de/de/studium/studiengaenge/fernstudium/M26/LM26>, Stand: 21.01.2022.
31 Tappenbeck / Meinhardt 2021, S. 6. Hier findet sich eine tabellarische Übersicht der Modulstruktur des Studiengangs.
32 Siehe Anm. 30. Auf der dort verlinkten Seite findet sich eine tabellarische Übersicht der Modulstruktur des Studiengangs.
33 Siehe <https://www.th-wildau.de/studieren-weiterbilden/studiengaenge/bibliotheksinformatik-msc-berufsbegleiten
des-studium/>, Stand: 10.02.2022.
34 Zumindest indirekt belegt ist dies bei Kraus 2020, Kap. 4.2 und 4.3.
35 Leider thematisieren Tappenbeck / Meinhardt 2021 in ihrer anregenden Darstellung des neuen MALIS-Studiengangs der TH Köln lediglich neue und beibehaltene Inhalte.
36 Exemplarisch sei auf den Zertifikatskurs Data Librarian der TH Köln verwiesen; siehe: <https://www.th-koeln.de/weiterbildung/zertifikatskurs-data-librarian_63393.php>, Stand: 19.11.2021. Siehe auch oben, Abschnitt 3.1.
37 Anschaulich hierzu Tappenbeck, die zehn Kernbereiche identifiziert hat, auf denen Fachreferent*innen Kenntnisse und Fähigkeiten haben müssten. Tappenbeck, Inka: Fachreferat 2020. From collections to connections, in: Bibliotheksdienst 49 (1), 2015, S. 37–48, hier S. 44f. Online: <https://doi.org/10.1515/bd-2015-0006>, Stand: 19.11.2021.
38 Tréfás, David: Das Fachreferat. Vom Universalgelehrten zur Schwarmintelligenz, in: Bibliotheksdienst 52 (12), 2018, S. 864–874, hier S. 871 (siehe ferner ebd. S. 871–874). Online: <https://doi.org/10.1515/bd-2018-0103>, Stand: 19.11.2021. Darüber hinaus ist festzuhalten, dass die zunehmende Aufgabenvielfalt eine bibliotheksübergreifende Kooperation nötig macht. Hierzu: Horstmann, Wolfram; Jahn, Najko; Schmidt, Birgit: Der Wandel der Informationspraxis in Forschung und Bibliothek, in: Zeitschrift für Bibliothekswesen und Bibliographie 62 (2), 2015, S. 73–79, hier S. 79. Online: <https://doi.org/10.3196/186429501562223>, Stand: 19.11.2021.
39 Die im Fachreferat nötige Spezialisierung betont bereits Enderle, Wilfried: Selbstverantwortliche Pflege bibliothekarischer Bestände und Sammlungen. Zu Genese und Funktion wissenschaftlicher Fachreferate in Deutschland 1909–2011, in: Bibliothek. Forschung und Praxis 36 (1), 2012, S. 24–31, hier S. 31. Online: <https://doi.org/10.1515/bfp-2012-0004>, Stand: 19.11.2021.
40 In diesem Sinne ist es zu begrüßen, dass im MALIS-Studiengang der TH Köln „[e]twa die Hälfte der Studienaufgaben (...) in Form von Gruppen- oder Tandemaufgaben absolviert“ wird. Tappenbeck / Meinhardt 2021, S. 8.
