
The Mobility Compass
A VIVO-based approach for exploring interdisciplinary research networks
Summary
With the increasing importance of interdisciplinary cooperation, the need for efficient and preferably platform-independent ways to search for suitable experts and network partners is also increasing. In the field of mobility and transport research, the Specialised Information Service Mobility and Transport Research (FID move) has developed a new and innovative tool for this purpose: the Mobility Compass. Using the already established open-source software VIVO, the Mobility Compass aggregates different databases and provides explorative ways for finding persons of interest. This article describes the technical conception of the tool and explains why VIVO is a suitable choice for this specific purpose. Furthermore, the main functionalities of the Mobility Compass are shown and the steps and challenges associated with their implementation are examined in more detail. Finally, the article deals with the reusability of the project results and gives a brief outlook on the next steps in the project.
Zusammenfassung
Mit zunehmender Bedeutung der interdisziplinären Zusammenarbeit steigt auch der Bedarf an effizienten und möglichst plattformunabhängigen Möglichkeiten zur Suche nach geeigneten Expert*innen und Netzwerkpartner*innen. Im Bereich der Mobilitäts- und Verkehrsforschung hat der Fachinformationsdienst Mobilitäts- und Verkehrsforschung (FID move) dazu ein neues und innovatives Werkzeug entwickelt: den Mobility Compass. Dieser basiert auf der bereits etablierten Open-Source-Software VIVO und aggregiert verschiedene Datenbanken, um über explorative Sucheinstiege interessante Personen möglichst zielführend zu finden. Der Artikel beschreibt die technische Konzeption des Mobility Compass und zeigt auf, warum VIVO für diesen speziellen Einsatzzweck geeignet ist. Darüber hinaus werden die zentralen Funktionalitäten erklärt sowie die mit der Implementierung verbundenen Schritte und Herausforderungen näher betrachtet. Der Artikel schließt mit der Wiederverwendbarkeit der Projektergebnisse und einem kurzen Ausblick auf die nächsten Schritte im Projekt.
This work is licensed under Creative Commons Attribution 4.0 International.
1. Motivation and goals
Scientific work is largely based on one’s own research networks and view of existing research fields. The importance of interdisciplinary cooperation is increasing in this context and is sometimes a decisive prerequisite for the successful application and implementation of research projects.1 However, this is accompanied by numerous challenges. These include the identification of relevant researchers outside of one’s own field of research or obtaining an overview and insight into existing scientific networks. Often, this is complicated by the use of differing technical terms for the same topics in each field. Furthermore, research networks are constantly evolving. Monitoring these changes becomes increasingly challenging as information about people is distributed over a variety of different platforms, e.g. institutional websites, ResearchGate or Academia.edu. Additionally, both personal networking and digital self-representation may be achieved with many different tools. This makes the search for and identification of new persons or topics, which are fundamental to interdisciplinary cooperation, sometimes very time-consuming and represents a cost factor.
The challenges described are particularly evident in the field of mobility and transport research with its numerous disciplines – from traffic engineering and traffic planning to computer science and medicine to sociology, to name just a few. To create sustainable solutions for the future, different disciplines must work closely together.2 This need to improve interdisciplinary exchange was one of the starting points of the “Specialised Information Service Mobility and Transport Research” (FID move) launched in 2018. The FID move3 is a DFG-funded cooperation project between the Saxon State and University Library Dresden (SLUB)4 and the German National Library of Science and Technology – Leibniz Information Centre for Science and Technology and University Library Hannover (TIB)5. The goal of the FID move is to develop and expand services and tools which support the mobility and transport research community throughout the entire research cycle. Particularly with regard to improving interdisciplinary collaboration, there was a need for a new tool that would make existing research networks visible and accessible and allow its users to identify potential cooperation partners. This approach was also intended to make the whole process for researchers more streamlined. The tool needed to be easy to use while at the same time it should offer innovative search results and be fun to use. Additionally, it needed to be easily adaptable, able to respond to changes in the scientists’ needs and be reusable by others. The result is called “Mobility Compass” and was developed by the SLUB.
2. Approach
An already existing and established software solution that both met the requirements of reusability and openness and offered an optimal starting point for the development of the tool was VIVO.6 This is an open-source current research information system (CRIS) and was used as a basis for the Mobility Compass. This innovative tool is used for gaining a quick and explorative insight into existing knowledge networks and exploring a diversity of selected disciplines. The Mobility Compass can be accessed at <www.mobility-compass.eu>.7
2.1. In detail: What VIVO is and how it works
VIVO is a web application written in Java and intended to represent scholarly work from usually only one specific research institution. Technically, it consists of two parts: first, a generic implementation without a business context called Vitro. This part can be used for any subject domain. It provides a browser-based ontology editor which allows a very simple extension of the data model. In addition, Vitro offers the possibility of browser-based data editing and presentation. The data is linked to ontologies following the concept of semantic web and stored in a native triplestore (also known as RDF store). RDF (Resource Description Framework) allows for a very generic storage and retrieval of data, which is completely independent from the particular use case. Vitro was initially developed by Cornell University8 in Ithaca, New York, and then given to the open VIVO community. The second part, VIVO, extends Vitro by the domain of research information. In particular, a specific ontology was added – the VIVO ontology. This ontology bundles and substantiates the semantic of data from the context of research information. For this purpose, established ontologies were included, e.g. FOAF for metadata of social networks.9 In addition, the frontend was extended for the presentation of research information.
Technically, VIVO is a Java EE web application running in a web container (often Tomcat). It uses FreeMarker10 as its template engine and Jena11 for the realisation of its triplestore. In addition, VIVO uses a search engine (configurable, but often Solr) to implement selected data queries in the frontend with high performance.
VIVO is characterized by its high degree of adaptability. The use of RDF in combination with the Linked Open Data paradigm and the use of established ontologies allows for machine readability of the stored data. The reuse of this data by other systems is supported by VIVO’s integrated interfaces for data transfer. For example, the SPARQL endpoint enables very specific data queries related to the individual needs. It is possible to retrieve any stored data. Using ListRDF API,12 records of a specific type can be listed, e.g. all publications. The Linked Open Data API13 allows the retrieval of all data from a specific object (e.g. a specific publication) using content negotiation resulting in the RDF/XML, N3, Turtle or JSON-LD format. Further important interfaces included in VIVO are a Triple Pattern Fragments API14 and a Direct2Experts API15.
2.2. Why VIVO is well suited for this specific purpose
VIVO is a fully operational CRIS software, which is provided by the academic consortium Lyrasis16. Several institutions worldwide already use VIVO, for instance, to represent their scholarships. Some examples are the Brown University17, the University of Wollongong18, the consortium UNAVCO, the TIB Hannover19, the Mittweida University of Applied Sciences20 and many more21. The constantly growing community ensures that the software is continuously enhanced and further developed. The core developer team is financed by voluntary Lyrasis memberships. Furthermore, due to its open structure, VIVO can be adapted to the user’s own specific needs. This is also supported by the integrated browser-based ontology editor, which makes the data model very easily extendable. In addition, VIVO already contains various interfaces for the transfer of data. The functionalities already include both the data ingest and the automated sharing of all data. This made it possible to focus on the specifics of the respective use case, in particular on the visual design (the theme), the addition of suitable front-end functionalities and specific data connections.
2.3. The Mobility Compass: A VIVO use case
The Mobility Compass serves to search for interesting contacts and offers an overview of existing research fields in the interdisciplinary domain of mobility and transport research. The exploratory procedure takes place in three steps: first, the search area is defined and thus, the number of relevant researchers is limited. Then a person is selected from the result list and the details view shown for the respective researcher. Finally, users are presented with various options to engage with the person and the associated network of researchers and research topics. These three steps are explained in more detail below.
To start the search, users first have two specific search options: “Topics” and “Locations”. Searching via Topics, users can select topics which are related to people and their research output, e.g. transport policy or urban traffic. The basis for the input of topics is a pre-defined vocabulary including synonyms. This was created on the basis of the Transportation Research Thesaurus (TRT)22 and is constantly being further developed. As a result of the topic selection, the Mobility Compass generates a topic graph (see figure 1). This graph represents a structure of topics in the context in which they are researched by the scientists. For this purpose, two topics are directly connected if they were both researched by the same scientists. This also creates a detailed insight into the inner structure of the field’s topic landscape.
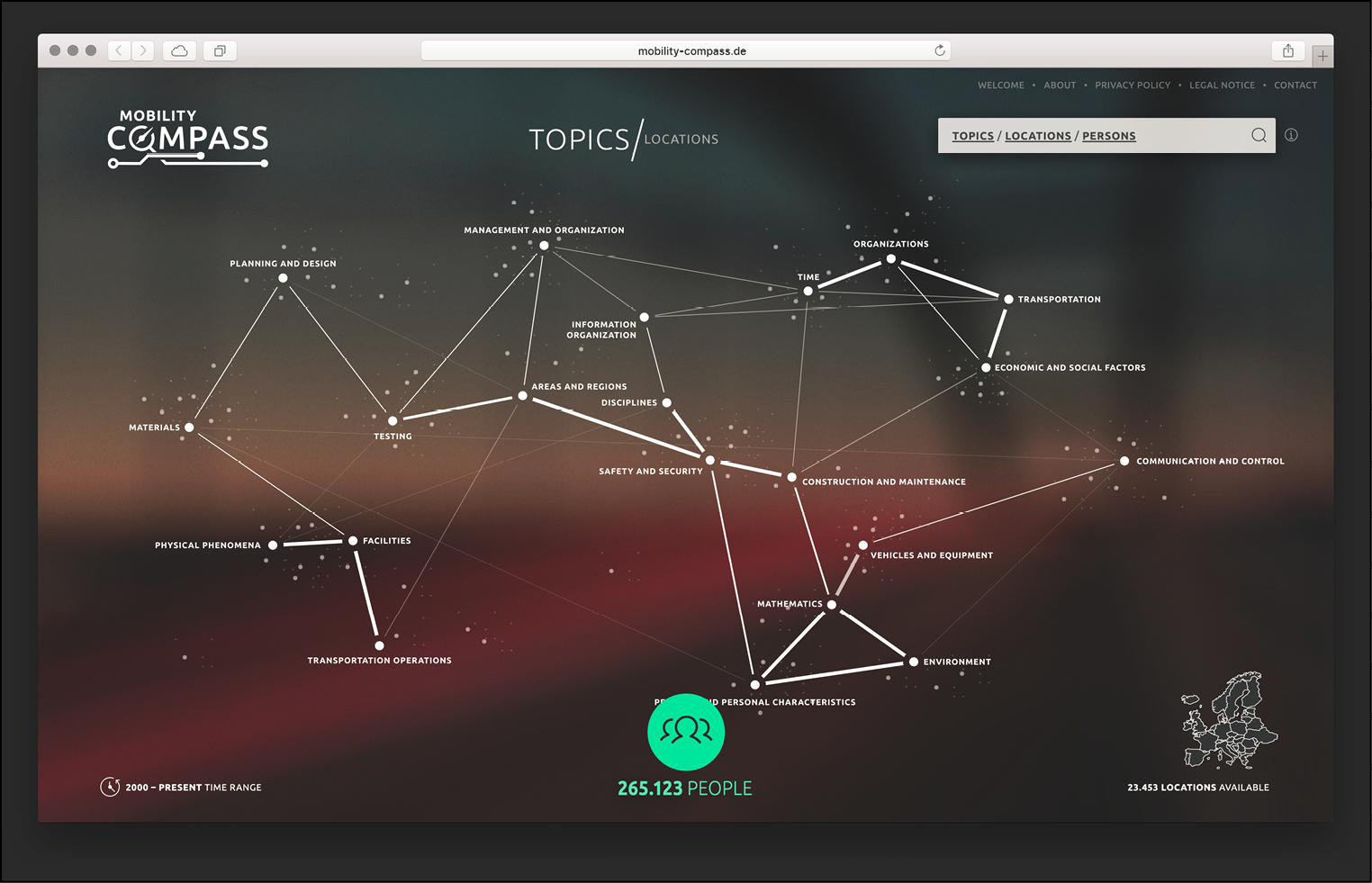
This provides a visual insight into the structure of the selected subject area and allows for an exploration of related research topics without requiring a deeper knowledge of the thematic systematics of the research field.
In addition to the search via topics, the Mobility Compass offers a location-based search (see figure 2). Starting the search with this option, a map provides information about the locations of scientists (esp. research institutions). Users can either look for relevant people at a certain location or people can be found by searching for topics or institutions. The map then simultaneously provides information about the locations of these people. Thus, the location search can provide insights into international research networks and the geographical distribution of selected researchers and topics.
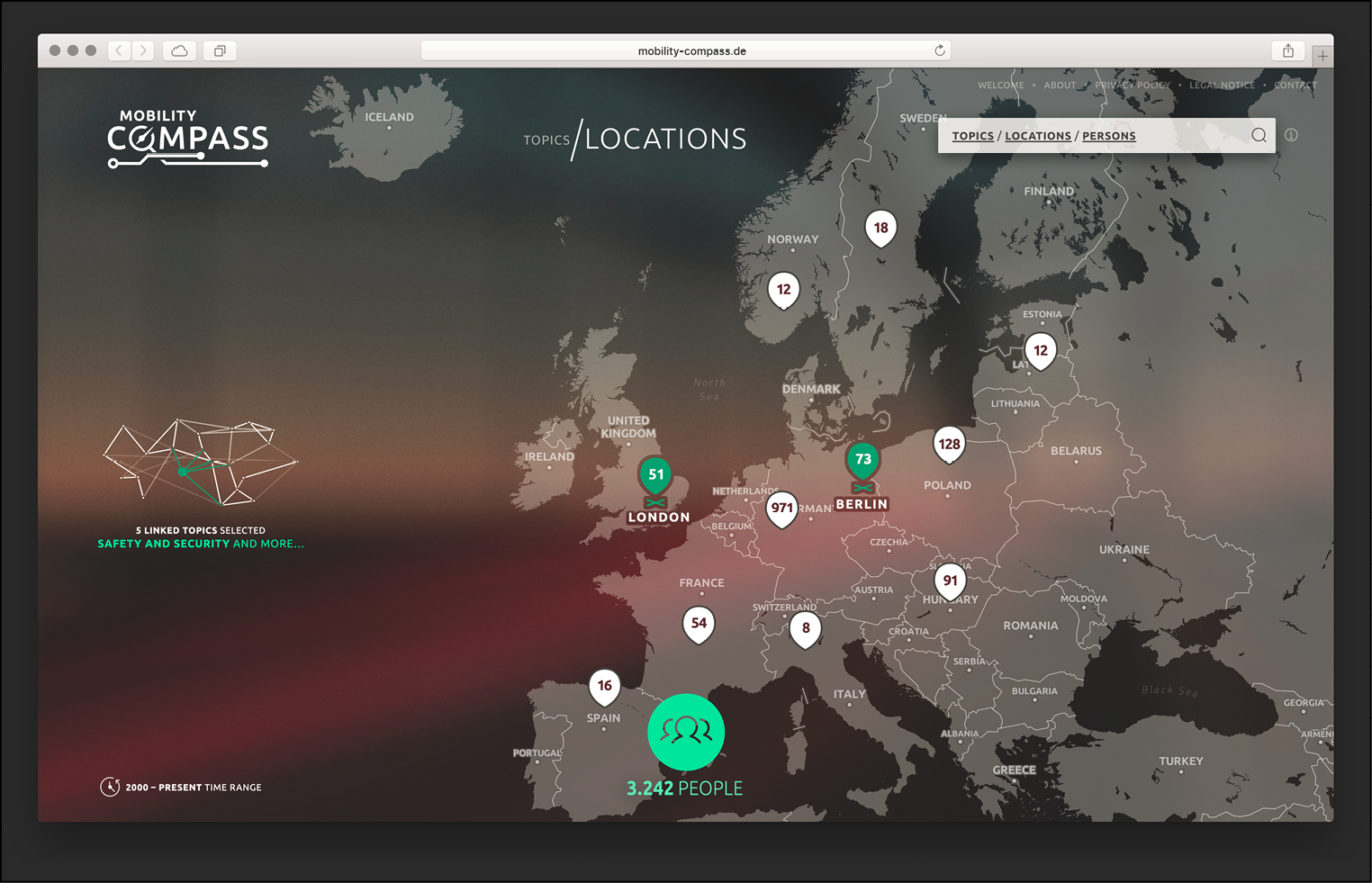
Both search options are interconnected and limit the number of relevant researchers in the results list. This list contains the names and institutions of all relevant persons. It can be further restricted, e.g. via the search function for conferences and institutes. Besides this, additional criteria such as the metric “number of citations” are presented for sorting. Finally, a click on a researcher’s name opens a detailed view of that person. It provides information on publications, related topics, statistics on research output as well as their connections to other researchers within the selected thematic realm (see figure 3).
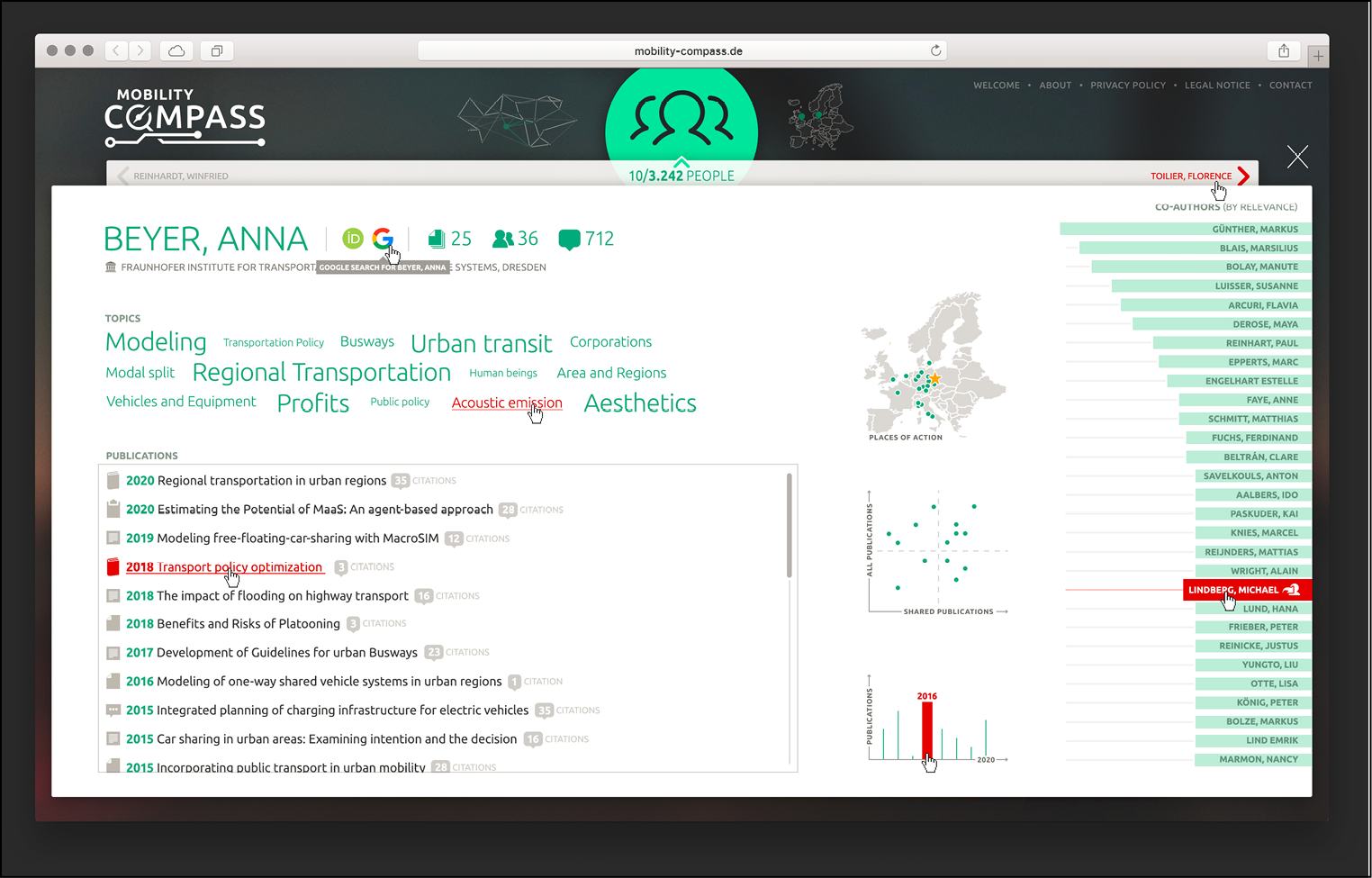
With the Mobility Compass, scientists gain a completely new way of exploring their expert communities and access to networks and structures they did not know or only partly knew about before.
2.4. Selection of the appropriate database excerpt on the example of the Mobility Compass
The selection and integration of relevant data is a decisive factor for the success of a tool like the Mobility Compass. The data included is currently based on publication databases (e.g. BASE23, Springer Nature), geographical databases containing institutions and locations (GRID24, GeoNames25), and bibliographic and citation databases (i.e. OpenCitations26). However, not all databases necessarily cover the subject-specific domain, or they contain data that goes beyond the desired thematic focus. Therefore, the source data needs to be filtered with regard to the appropriate data scope. Depending on the interdisciplinarity of the subject area, this can be a very complex, intellectually demanding task. Especially making a distinction between disciplines is a challenge to be mastered at this point.
There are several possibilities for solving this task, which can also be combined, depending on the data source. One starting point to filter the data sources are library classification systems, e.g. the Dewey Decimal Classification (DDC). With the help of the metadata added during cataloguing, a subject-specific selection can be compiled. This method is especially useful for well-indexed data sources. However, since some data sources are quite variably indexed, or only to a limited extent due to lightweight automatic classification of a low level of detail, there is a risk that the subject selection is either too small or includes too many unwanted hits. Therefore, a close cooperation with librarians during the filtering process is recommended.
Another approach is filtering on the basis of free keywords. This has proven to be effective but also time demanding. For this purpose, thematically matching words or groups of words are identified and then queried via selected fields of the metadata. In the presented case of the Mobility Compass, these are the title, abstract and keywords of the publications. Because of the use of a certain vocabulary or specific terms in other disciplines, a pure keyword search often results in false positives matches that do not actually belong in the hit list. For the area of transport and mobility, for example, these are terms such as “traffic” or “network”. Search words which are not sufficiently specific therefore require a corresponding context.
In addition to filtering by topic or keyword, it is also possible to limit the data to be included geographically. In the use case of the Mobility Compass, right from the start the community had expressed the need to view and search the corresponding networks for at least the entire European area instead of single countries.
With the Mobility Compass, other challenges arose in this context. For example, currently not all sources with potentially relevant content can be integrated into the tool. Private-sector data owners such as ResearchGate restrict the reuse of their data, although it is often entered by researchers voluntarily and free of charge. The initial focus of the Mobility Compass was therefore to integrate and link data from freely accessible data sources. So it had to be ensured that the reuse of data is possible and authorized. Furthermore, each data source uses its own thematic vocabulary (DDC, free keywords etc.). Thus, a subject search was not available at first, as sometimes different terms with the same meaning were used and so, an aggregation over the topics was not possible. The solution was to match all the topic information delivered from the source systems with the terminology of the TRT in an automated process. Finally, it should be noted that it might be difficult to differentiate between specific disciplines in the field of mobility and transport research. Different terminologies or approaches to the content of the research output make it difficult to narrow down the content. In order to create a subject-oriented and specific data basis for the desired use case, a close cooperation between IT, representatives of the field (subject specialists), as well as employees from scientific institutions (e.g. libraries) is necessary.
Speaking more technically: The Mobility Compass provides specific process pipelines to implement the connections to the various data sources. The collection, filtering, enrichment and linking of data is implemented with Python. This is followed by mapping and RDF transformation using Karma27. The data resulting from the respective pipeline is loaded into VIVO via the SPARQL endpoint.
3. Conclusion and outlook
Based on the open software VIVO, a new and innovative tool called Mobility Compass has been developed and made available.28 On the one hand, this tool simplifies the search for relevant research partners and scientific networks. It offers a higher level of transparency in unfamiliar or little-known fields of research. On the other hand, it enables rather little or unknown research networks or fields of expertise to gain a higher visibility. It therefore increases the reach of scientists.
Furthermore, the tool and its aggregated data is available for subsequent use by other disciplines in the field of research information. We intend to make the user interface of the Mobility Compass freely available for reuse.
For the next project phase, there are plans to enhance the scope and the quality of the data even further. An essential component of this is the improvement of subject indexing through artificial intelligence technologies. The automated mapping to the TRT carried out in the first phase will be expanded using machine learning techniques. These aim to achieve a higher degree of abstraction in automated subject indexing so that even topics that do not appear literally in an academic text can be identified. An additional component is to support and motivate scientists to use ORCID (Open Researcher and Contributor ID) in order to improve the findability and assignability of their research output in the various data sources. Last but not least, we plan to develop a widget for embedding the Mobility Compass into other websites. This provides the basis for integration into content management systems regardless of the platform used.
References
- Conlon, Michael; Woods, Andrew; Triggs, Graham et al: VIVO: a System for Research Discovery, in: Journal of Open Source Software 4 (39), 2019, 1182, <https://doi.org/10.21105/joss.01182>.
- Gleed, Alasdair; Marchant, David: Interdisciplinarity. Survey Report for the Global Research Council 2016. Cheshire 2016, <https://www.globalresearchcouncil.org/fileadmin/documents/GRC_Publications/Interdisciplinarity_Report_for_GRC_DJS_Research.pdf>, last accessed 04.02.2021.
- Rau, Henrike; Scheiner, Joachim: Sustainable Mobility: Interdisciplinary Approaches, in: Sustainability 12 (23), 2020, 9995, <https://doi.org/10.3390/su12239995>.
1 Gleed, Alasdair; Marchant, David: Interdisciplinarity. Survey Report for the Global Research Council 2016. Cheshire 2016, <https://www.globalresearchcouncil.org/fileadmin/documents/GRC_Publications/Interdisciplinarity_Report_for_GRC_DJS_Research.pdf>, last accessed 04.02.2021.
2 Rau, Henrike; Scheiner, Joachim: Sustainable Mobility: Interdisciplinary Approaches, in: Sustainability 12 (23), 2020, 9995, <https://doi.org/10.3390/su12239995>.
3 FID move, <https://fid-move.de>, last accessed 04.02.2021.
4 For information on the SLUB cf. <https://ror.org/03wf51b65>.
5 For information on the TIB cf. <https://ror.org/04aj4c181>.
6 Conlon, Michael; Woods, Andrew; Triggs, Graham et al.: VIVO: a System for Research Discovery, in: Journal of Open Source Software 4 (39), 2019, 1182, <https://doi.org/10.21105/joss.01182>.
7 Please note that the system is currently undergoing intensive revision. At the time of publication it is still called “Forschungskompass”. All information and images in the text refer to the concept for the new major release.
8 For information on Cornell University cf. <https://ror.org/05bnh6r87>.
9 The source ontologies for VIVO can be found under <https://wiki.lyrasis.org/display/VIVODOC111x/Source+ontologies+for+VIVO>, last accessed 04.02.2021.
10 Apache FreeMarker, <https://freemarker.apache.org>, last accessed 04.02.2021.
11 Apache Jena, <https://jena.apache.org>, last accessed 04.02.2021.
12 The ListRDF API is an interface integrated in VIVO to provide lists of objects of a requested class. More details can be found under <https://wiki.lyrasis.org/display/VIVODOC111x/ListRDF+API>, last accessed 04.02.2021.
13 The Linked Open Data API provides all data of a requested object, e.g. a specific person. More details can be found under <https://wiki.lyrasis.org/display/VIVODOC111x/Linked+Open+Data+-+requests+and+responses>, last accessed 04.02.2021.
14 The Linked Data Fragments API allows for fast receipt of data. Implementation details can be found under <https://github.com/LinkedDataFragments/Server.Java>, last accessed 04.02.2021.
15 The Direct2Experts API allows other applications to search for an expert in the requested VIVO instance. More details can be found under <http://direct2experts.org/>, last accessed 04.02.2021.
16 Lyrasis, <https://www.lyrasis.org>, last accessed 04.02.2021.
17 Researchers@Brown, <https://vivo.brown.edu/>, last accessed 04.02.2021.
18 UOW Scholars, <https://scholars.uow.edu.au>, last accessed 04.02.2021.
19 TIB VIVO, <https://vivo.tib.eu>, last accessed 04.02.2021.
20 VIVO@HSMW, <https://vivo.hs-mittweida.de>, last accessed 04.02.2021.
21 The VIVO registry can be found under <https://duraspace.org/registry/?filter_10=VIVO>, last accessed 04.02.2021.
22 Transportation Research Thesaurus, <https://trt.trb.org/trt.asp>, last accessed 04.02.2021.
23 Bielefeld Academic Search Engine (BASE), <https://www.base-search.net>, last accessed 04.02.2021.
24 Global Research Identifier Database (GRID), <https://www.grid.ac>, last accessed 04.02.2021.
25 GeoNames, <https://www.geonames.org>, last accessed 04.02.2021.
26 OpenCitations, <https://opencitations.net>, last accessed 04.02.2021.
27 Karma is an open-source ETL Tool (Extract, Transform, Load) which allows for the mapping and transformation of relational data to RDF. More details can be found at <https://usc-isi-i2.github.io/karma>, last accessed 04.02.2021.
28 Visit <www.mobility-compass.eu> to try it and share your feedback with us.
